




尊敬的 Databenders,在 Databend Labs 成立两周年之际,我们非常高兴地宣布 Databend v1.0 正式发布。
Databend 社区一直在致力于解决大数据分析的成本和复杂度问题,并正在被顶级场景和顶级需求所推动。 根据可统计信息,每天约 700TB 数据在使用 Databend 写入到云对象存储并进行分析,用户来自欧洲、北美、东南亚、非洲、中国等地,每月为他们节省数百万美元成本。 Databend v1.0 是一个具有里程碑意义的版本,我们相信它将进一步加速云端海量数据分析的发展。
今天,我将首先介绍 Databend v1.0 相比 v0.9 版本所做的改进,然后探讨我们团队的愿景和未来展望。现在就让我们开始吧!
v1.0 改进
Databend 在版本 v1.0 中实现了惊人的性能提升,在 ClickBench 测试中获得:数据加载第一名,在查询环节,c6a.4xlarge 第一名,c5a.4xlarge 第二名,c6a.metal 第三名
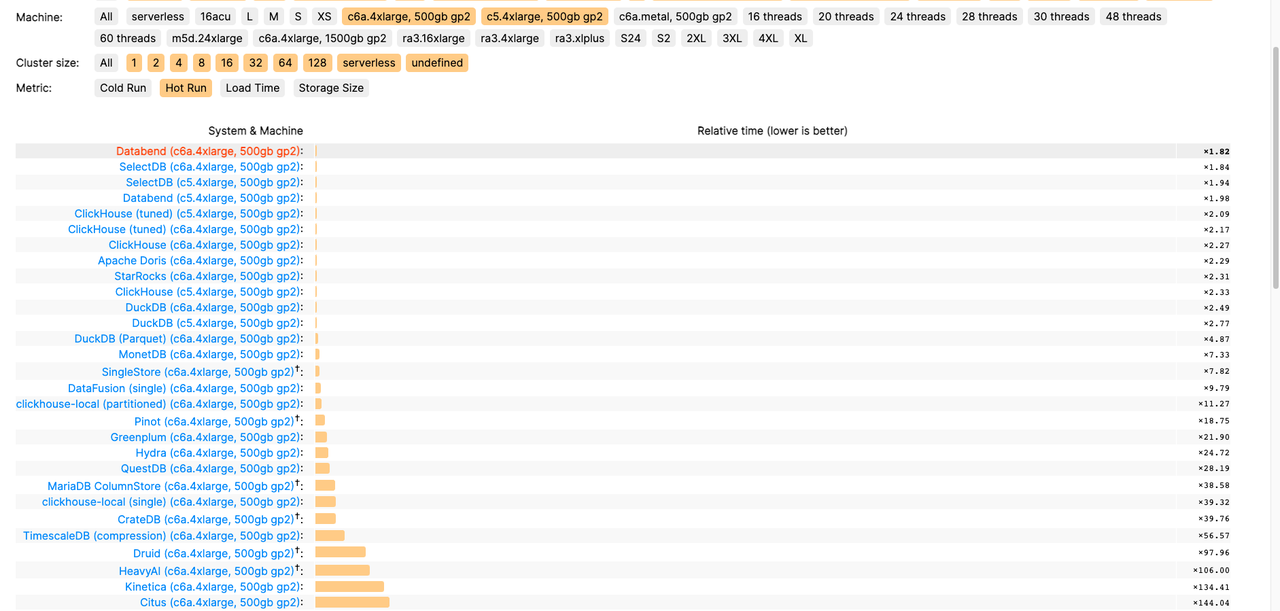
此外,Databend 社区还在版本 v1.0 中推出了多项新功能:
UPDATE
现在,用户可以使用 UPDATE 语句来更新 Databend 中的数据。
更新语句的格式如下:
-- Update a book (Id: 103)
UPDATE bookstore SET book_name='The long answer (2nd)' WHERE book_id=103;
通过支持 UPDATE 功能,Databend 实现了对 CRUD 操作的完整支持。
ALTER TABLE
在 v1.0 中,用户可以使用 ALTER TABLE 来修改 Databend 中的表结构:
-- Add a column
ALTER TABLE t ADD COLUMN c Int DEFAULT 10;
DECIMAL
在完成了 Databend 类型系统的大型重构之后,社区在一个坚实的基础上实现了 DECIMAL 数据类型的支持!
-- Create a table with decimal data type.
create table tb_decimal(c1 decimal(36, 18));
-- Insert two values.
insert into tb_decimal values(0.152587668674722117), (0.017820781941443176);
select * from tb_decimal;
+----------------------+
| c1 |
+----------------------+
| 0.152587668674722117 |
| 0.017820781941443176 |
+----------------------+
Native Format
在 v0.9 版本中引入的 Native Format strawboat 得到了进一步的完善!社区为 strawboat 增加了半结构化数据的支持,并引入了多项性能优化,帮助 Databend 在 HITS 数据集的性能取得了巨大提升。
CBO
引入了直方图框架,可以利用统计信息更为精确地进行代价估算。进一步完善和强化 join reorder 算法,从而大大的提高多表 join 的性能,帮助 Databend 在 TPCH 数据集上的性能取得显著提升。
SELECT FROM STAGE
STAGE 是 Databend 数据流转的核心。我们之前已经支持从 STAGE 中加载数据和向 STAGE 中导出数据,现在我们更进一步,支持了直接在 STAGE 中进行数据查询!
用户只需要为 Databend 创建一个包含数据文件的 STAGE,就可以轻松进行数据查询,无需编写复杂的建表语句或繁琐的数据导入流程。
select min(number), max(number) from @lake (pattern => '.*parquet');
+-------------+-------------+
| min(number) | max(number) |
+-------------+-------------+
| 0 | 9 |
+-------------+-------------+
如果用户只需要进行一次性的查询,还可以直接使用更简短的 URI 形式:
select count(*), author
from 'https://datafuse-1253727613.cos.ap-hongkong.myqcloud.com/data/books.parquet' (file_format => 'parquet')
group by author;
+----------+---------------------+
| count(*) | author |
+----------+---------------------+
| 1 | Jim Gray |
| 1 | Michael Stonebraker |
+----------+---------------------+
Query Result Cache
在 v1.0 版本中,Databend 社区借鉴了 ClickHouse 社区的设计,并增加了 Query Result Cache 功能。当底层数据没有发生变化时,执行相同的查询会命中缓存,避免了重复执行查询的过程。
MySQL [(none)]> SELECT WatchID, ClientIP, COUNT(*) AS c, SUM(IsRefresh), AVG(ResolutionWidth)
FROM hits
GROUP BY WatchID, ClientIP ORDER BY c DESC LIMIT 10;
+--------------------+-------------+-----+----------------+----------------------+
| watchid | clientip | c | sum(isrefresh) | avg(resolutionwidth) |
+--------------------+-------------+-----+----------------+----------------------+
| 6655575552203051303| 1611957945 | 2 | 0 | 1638.0 |
| 8566928176839891583| -1402644643 | 2 | 0 | 1368.0 |
| 7904046282518428963| 1509330109 | 2 | 0 | 1368.0 |
| 7224410078130478461| -776509581 | 2 | 0 | 1368.0 |
| 5957995970499767542| 1311505962 | 1 | 0 | 1368.0 |
| 5295730445754781367| 1398621605 | 1 | 0 | 1917.0 |
| 8635802783983293129| 900266514 | 1 | 1 | 1638.0 |
| 5650467702003458413| 1358200733 | 1 | 0 | 1368.0 |
| 6470882100682188891| -1911689457 | 1 | 0 | 1996.0 |
| 6475474889432602205| 1501294204 | 1 | 0 | 1368.0 |
+--------------------+-------------+-----+----------------+---------------------+
10 rows in set (3.255 sec)
MySQL [(none)]> SELECT
WatchID, ClientIP, COUNT(*) AS c, SUM(IsRefresh), AVG(ResolutionWidth)
FROM hits
GROUP BY WatchID, ClientIP ORDER BY c DESC LIMIT 10;
+---------------------+-------------+------+----------------+--------------+
| watchid | clientip | c | sum(isrefresh)| avg(resolutionwidth) |
+---------------------+-------------+------+----------------+-------------+
| 6655575552203051303 | 1611957945 | 2 | 0| 1638.0 |
| 8566928176839891583 | -1402644643 | 2 | 0| 1368.0 |
| 7904046282518428963 | 1509330109 | 2 | 0| 1368.0 |
| 7224410078130478461 | -776509581 | 2 | 0| 1368.0 |
| 5957995970499767542 | 1311505962 | 1 | 0| 1368.0 |
| 5295730445754781367 | 1398621605 | 1 | 0| 1917.0 |
| 8635802783983293129 | 900266514 | 1 | 1| 1638.0 |
| 5650467702003458413 | 1358200733 | 1 | 0| 1368.0 |
| 6470882100682188891 | -1911689457 | 1 | 0| 1996.0 |
| 6475474889432602205 | 1501294204 | 1 | 0| 1368.0 |
+---------------------+-------------+---+---------------+-----------------+
10 rows in set (0.066 sec)
Table Data Cache
缓存是存算分离架构中的重要组成部分。在 v1.0 版本中,Databend 社区为我们带来了 Table Data Cache!当 Databend 执行查询时,会根据访问数据的热度情况决定是否将该数据块保存到缓存中,以加速下一次访问。
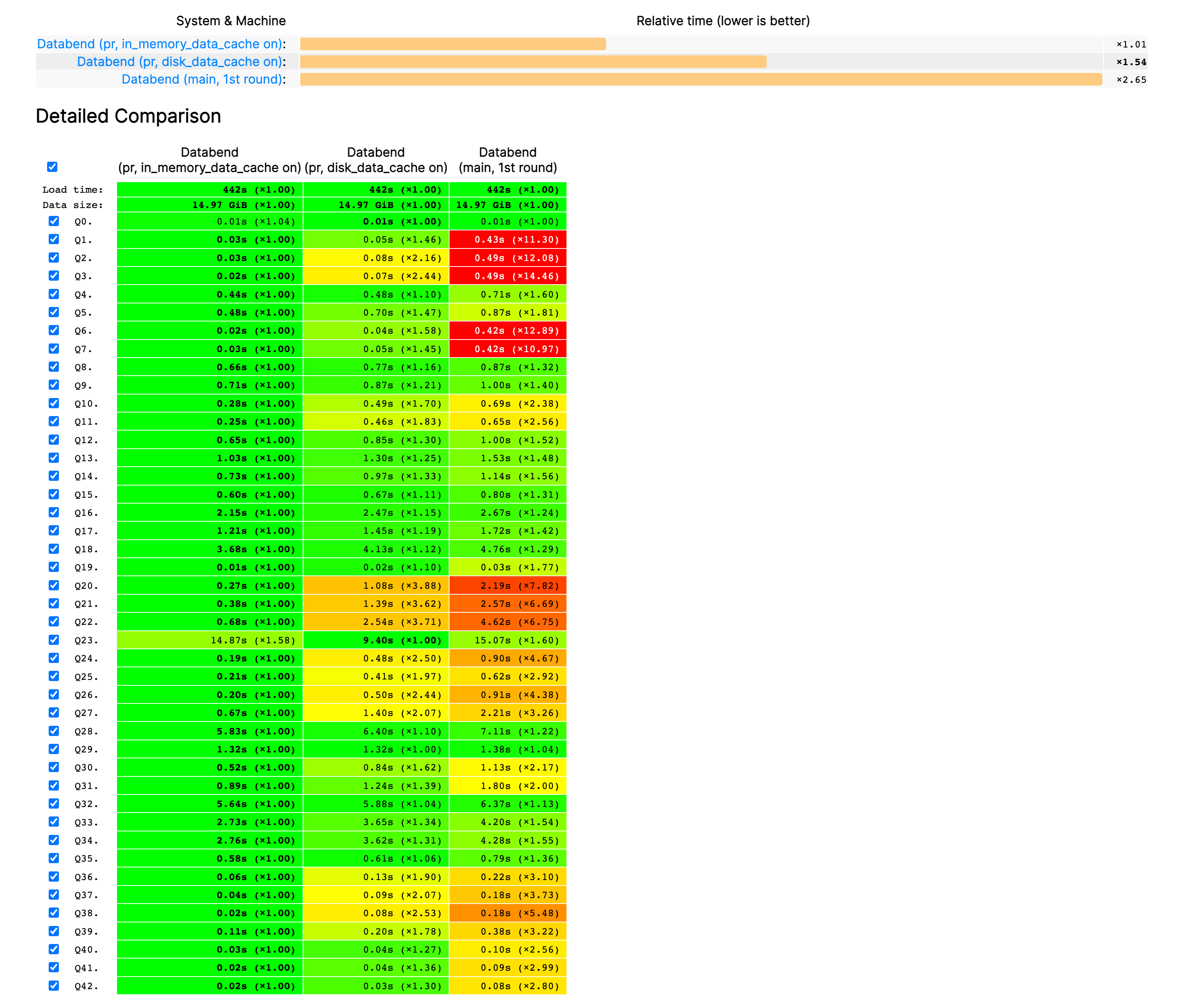
Aggregate Spill
在 v1.0 版本中,Databend 引入了 Aggregate spill, 当在 Databend 中执行聚合查询时,会根据 Databend 当前的内存使用情况动态决定将内存中的聚合数据临时保存并持久化到对象存储中,防止查询过程中使用过高的内存。
未来展望
经过这些版本的打磨,Databend 终于有了一个雏形。现在,让我们重新认识一下 Databend:
-
一个使用 Rust 开发的云原生数据仓库:存算分离,面向对象存储设计,极致弹性
-
支持完整的 CRUD 特性,提供了 MySQL/Clickhouse/HTTP RESTful 等协议支持
-
提供原生的 ARRAY、MAP、JSON 等复杂类型和 DECIMAL 高精度类型支持
-
构建了类似于 Git 的 MVCC 列式存储引擎,支持 Data Time Travel 和 Data Share 能力
-
不受存储供应商的限制,可以在任何存储服务上运行,并直接查询任何存储服务上的数据
-
目前已全面支持 HDFS/Cloud-Based Object Storage 协议,包括:阿里云 OSS,腾讯云 COS,华为云 OBS,以及 S3,Azure Blob, Google Cloud Storage
Databend 的征程远远不止于此,在未来我们希望 Databend 能拥有:
更强大的功能
在紧随其后的 v1.1 版本中,我们希望实现如下功能:
-
JSON 索引:提高半结构化数据检索能力
-
分布式 Ingest 能力:提高数据写入速度
-
MERGE INTO 功能:实现数据源增、删、改的实时 CDC 能力
-
Windows Function
我们希望这些功能能进一步满足用户的需求,并且实现 Databend 在 CDC 场景下的突破。
更开放的社区
Databend Labs 由一群开源爱好者组成,Databend 项目从创建之初就是采用 Apache 2.0 协议授权的开源项目。在借鉴和吸收 ClickHouse,CockroachDB 等开源项目优秀思想的同时,我们也在以自己的方式回馈社区:
-
开源了 Databend 元数据服务集群的共识引擎 Openraft
-
向 Apache 软件基金会捐赠了底层的数据访问引擎 OpenDAL 并成功进入孵化器开始孵化
-
成为向量计算基础库 arrow2 等多个依赖项目的贡献者
-
跟进并采用 Rust Nightly,帮助 Rust 社区复现并验证问题
没有开源社区就没有今天的 Databend,感谢 144 个参与 Databend 的贡献者!接下来,我们将更开放地与其他开源社区合作,支持读写 Iceberg、Delta Lake 等格式,打破数据间的壁垒,使数据能够更自由灵活地流转。
感谢大家!
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
Databend Cloud: https://databend.cn
Databend 文档:https://docs.databend.cn/
Wechat:Databend
GitHub: https://github.com/databendlabs/databend
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


