




在单机模式下我们部署了 databend-meta 和 databend-query 两种角色(参考:基于 minio 部署单实例 Databend ),其中 databend-query 是计算节点,无状态模式,这种架构也有直接用于生产的。实际上生产环境推荐至少部署三个 databend-meta 组成集群,databend-query 可以是一个节点,而且可做到不使用就关闭。如果你使用的是公有云上对象存储,就不用担心对象存储的高可用。下面我们描述一下 Databend 的集群环境搭建。
Databend 集群中的概念
在 Databend 集群中分为两个角色:databend-meta 集群和 databend-query 集群。其中 databend-meta 集群要求先启动,它在生产环境中建议 awayson 状态,并至少 3 个节点;databend-query 集群,可以是多个。
在生产中,我们推荐可以全局部署一个 databend-meta 集群,databend-meta 对资源消耗不高,可以和其它程序共用资源。
databend-query 默认是最大能力的并发,在单个 databend-query 节点下,一个 SQL 会尽最大努力把单节点的所有 CPU CORE 间并发;在集群模式下,databend-query 会把计算在整个集群中做并发调度。
集群资源隔离
在 databend 集群中,资源隔离有几个重要的概念:tenant_id , cluster_id, max_threads 为了让大家更好的理解 databend 集群,我们需要先理解一下这三个概念。
-
tenant_id 称为:租户 id,用于标识 databend-query 属于哪个租户下面,当租户 tenant_id 一样时,这个 databend-query 就可以获取该租户下的:用户列表及权限,对应的数据的定义相关等。
-
cluster_id 称为:集群 id , 这个参数依附于 tenant_id,需要首先看它在哪个 tenant_id 下面,然后可以获取对应的 meta 数据,之后再看是不是有同样的 cluster_id 成员。如果遇到同样的 cluster_id 成员就自动组成集群,可以在 system.clusters 表中查询到,SQL 请求到该节点后,算力会在 tenant_id 和 cluster_id 一样的节点间协调。对于 tenant_id 一样,cluster_id 不一样的,可以起到算力隔离,但大家共享一份数据和用户列表。
-
max_threads 控制一个 sql 在 databend-query 上可以用到多少个 cpu core, 默认是节点支持的 cpu core,例如有一些复杂 SQL 在内存不足的情况下通过 max_threads 限制并发的数量,减少内存的占用。

databend-meta 集群
假设 databend-meta 集群三个节点:192.168.1.100,192.168.1.101,192.168.1.102 这三个节点上同时部署 databend-query 架构如下:
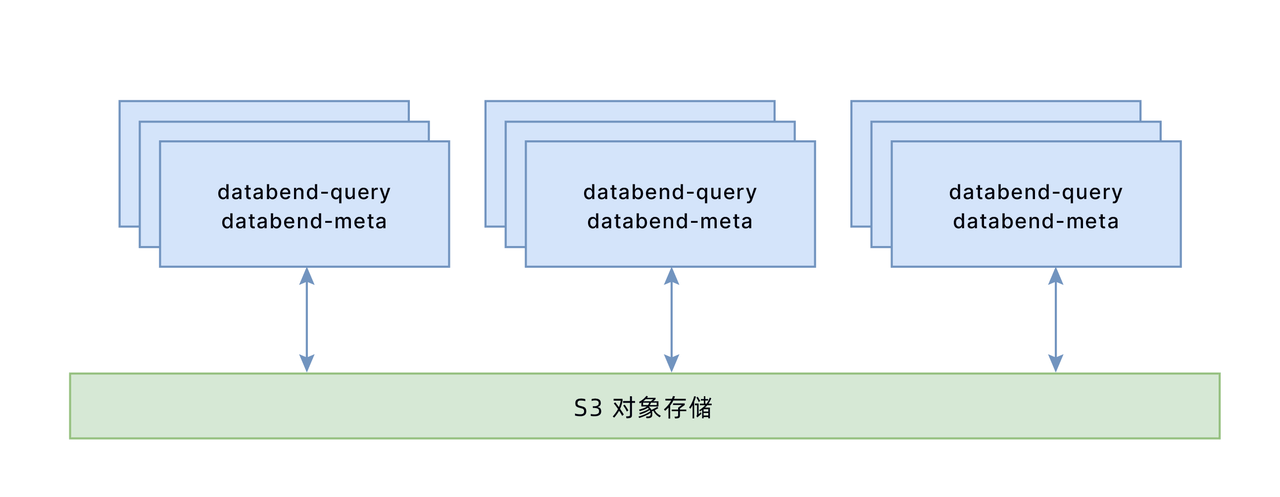
大概搭建信息如下:
| 节点 | ip | id |
|---|---|---|
| 192.168.1.100 | 192.168.1.100 | 1 |
| 192.168.1.101 | 192.168.1.101 | 2 |
| 192.168.1.102 | 192.168.1.102 | 3 |
其中配置文件中:raft_advertise_host 建议配置成 hostname 或是域名,这个需要 databend-meta 之间可以 ping 通及建立连接。可以暴力的修改 /etc/hosts
192.168.1.100 meta100
192.168.1.101 meta101
192.168.1.102 meta102
第一个节点(192.168.1.100),需要声明一个 single 节点
# databend-meta -c databend-meta-node-1.toml
log_dir = "./.databend/logs1"
admin_api_address = "0.0.0.0:28101"
grpc_api_address = "0.0.0.0:9191"
[raft_config]
id = 1
raft_dir = "./.databend/meta1"
raft_api_port = 28103
# Assign raft_{listen|advertise}_host in test config.
# This allows you to catch a bug in unit tests when something goes wrong in raft meta nodes communication.
# 为了安全,建议更改为内网 IP
raft_listen_host = "192.168.1.100"
# 如果配置成 hostname,需要注意 /etc/hosts 中可以解析
raft_advertise_host = "192.168.1.100"
# Start up mode: single node cluster
single = true
第二个节点 (192.168.1.101) 配置
# databend-meta -c databend-meta-node-1.toml
log_dir = "./.databend/logs1"
admin_api_address = "0.0.0.0:28101"
grpc_api_address = "0.0.0.0:9191"
[raft_config]
id = 2
raft_dir = "./.databend/meta1"
raft_api_port = 28103
# Assign raft_{listen|advertise}_host in test config.
# This allows you to catch a bug in unit tests when something goes wrong in raft meta nodes communication.
# 为了安全,建议更改为内网 IP
raft_listen_host = "192.168.1.101"
# 如果配置成 hostname,需要注意 /etc/hosts 中可以解析
raft_advertise_host = "192.168.1.101"
# Start up mode: single node cluster
#single = true
join =["192.168.1.100:28103","192.168.1.102:28103"]
注意 join 节点里不能出现本机的 ip
第三个节点(192.168.1.102)配置
# databend-meta -c databend-meta-node-1.toml
log_dir = "./.databend/logs1"
admin_api_address = "0.0.0.0:28101"
grpc_api_address = "0.0.0.0:9191"
[raft_config]
id = 3
raft_dir = "./.databend/meta1"
raft_api_port = 28103
# Assign raft_{listen|advertise}_host in test config.
# This allows you to catch a bug in unit tests when something goes wrong in raft meta nodes communication.
# 为了安全,建议更改为内网 IP
raft_listen_host = "192.168.1.102"
# 如果配置成 hostname,需要注意 /etc/hosts 中可以解析
raft_advertise_host = "192.168.1.102"
# Start up mode: single node cluster
#single = true
join =["192.168.1.100:28103","192.168.1.101:28103"]
注意 join 节点里不能出现本机的 ip
databend-meta 启动
meta.sh
#---
ulimit -n 65535
nohup bin/databend-meta --config-file=configs/databend-meta.toml
2>&1 >meta.log &
#end
./meta.sh
分别在三个节点启动 databend-meta, 如果启动出错及连接上不集群的情况,可以查看 .databend/logs 下面对应的日志,获取详细的说明。
Databend-meta 集群成员查看
curl 192.168.1.100:28101/v1/cluster/nodes
Databend query 集群
Query 节点的配置可以是一样的。需要注意以下
#这个地址需要改改成每台机器的 IP,如果 meta 不在本机可以用 0.0.0.0
flight_api_address = "192.168.1.100:9090"
#flight_api_address = "192.168.1.101:9090"
#flight_api_address = "192.168.1.102:9090"
#flight_api_address = "0.0.0.0:9090"
...
tenant_id = "test_tenant"
cluster_id = "test_cluster"
...
[meta]
# To enable embedded meta-store, set address to "".
embedded_dir = "./.databend/meta_embedded_1"
endpoints = ["192.168.1.100:9191","192.168.1.101:9191","192.168.1.102:9191"]
username = "root"
password = "root"
client_timeout_in_second = 60
auto_sync_interval = 60
其它可以保持一致,启动 databend-query 就可以加到一个集群,Databend query 启动建议参考 script 下面的 start.sh 修改后,或是直接启动。
可以根据 script/start.sh 修改出对应的启动脚本。生产中也可以考虑反 databend-meta 和 databend-query 加到 systemd 中管理。
第一次需要注意,首先需要启第一个 single 等 true 的节点,然后启动其它节点。第一次启动外,也需要注意,至少保证启动两个 meta 节点后,再启动 query 节点,否则可能出现 query 加不到集群的现象。
确认集群成员:
select * from system.clusters;
集群遇到问题
- Q1 databend-meta 进程启动 Ok,但集群成员列表查不 databend-meta 节点
这类错误通常在 databend-meta 对应的 logs 可以看到详细的报错提示
{"v":0,"name":"databend-meta","msg":"[JOIN_CLUSTER - START]","level":30,"hostname":"fz001.databend.cn","pid":170519,"time":"2022-10-20T06:22:15.767468275Z","target":"databend_meta::meta_service::raftmeta","line":559,"file":"src/meta/service/src/meta_service/raftmeta.rs"}
{"v":0,"name":"databend-meta","msg":"[JOIN_CLUSTER - EVENT] meta node is already initialized, skip joining it to a cluster","level":30,"hostname":"fz001.databend.cn","pid":170519,"time":"2022-10-20T06:22:15.767471165Z","target":"databend_meta::meta_service::raftmeta","line":573,"file":"src/meta/service/src/meta_service/raftmeta.rs"}
{"v":0,"name":"databend-meta","msg":"[JOIN_CLUSTER - END]","level":30,"hostname":"fz001.databend.cn","pid":170519,"time":"2022-10-20T06:22:15.767472905Z","target":"databend_meta::meta_service::raftmeta","line":559,"file":"src/meta/service/src/meta_service/raftmeta.rs"}
原因:该进程已经启动过,已经拥有数据,该节点会拒绝加入其它集群。如果需要他加入集群,需要清理一下对应节点的记录。
例如:
rm -rf .databend/meta/*
# 然后再次启动
nohup bin/databend-meta --config-file=configs/databend-meta.toml 2>&1 >meta.log &
对应修复的 PR:https://github.com/databendlabs/databend/issues/8383
如果你使用 databend-v0.8.85 后面的版本应该不会存在这个问题。
-
Q2 Databend-meta 集群,如何删掉一个成员
- 获取需要删除节点的 id 例如:id=3
- 利用成员查找找到成员信息
databend-meta --leave-id 3 --leave-via raft_listen_host:raft_api_port
如:
databend-meta --leave-id 3 --leave-via 192.168.1.100:28103
其中 leave-via 需要传入一个存活的节点信息。
- Q3 退出的节点怎么加回到集群
参考 Q1 需要清理一下对应的数据,保证 id 在集群中是唯一的,启动就可以。
- Q4 Databend-query 集群中只有一个成员:127.0.0.1:9090 看不到其它成员是怎么回事?
Databend Cluster 成员标识实质上用的:flight_api_address = "0.0.0.0:9090" 如果 databend-meta 和 databend-query 在同一个节点,就容易被识别为 127.0.0.1:9090,处理办法可以更改一下:flight_api_address = "0.0.0.0:9090" 中的 0.0.0.0 为本地局域网 IP 即可。
-
Q5 Databend-query 如何划分集群
Databend-query 依据 tenant_id = "test_tenant" cluster_id = "test_cluster" 属于那个租户和那个集群,同一个 teant_id 下 meta 相应的信息是共享的,相应的 cluster_id 是计算可以共享。所以 Databend 中支持原生的多租户模型,同一个租户内也支持多个 Cluster,多 Cluster 场景主要用于算力隔离,同时共享一份数据。
Connect With Us
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


