




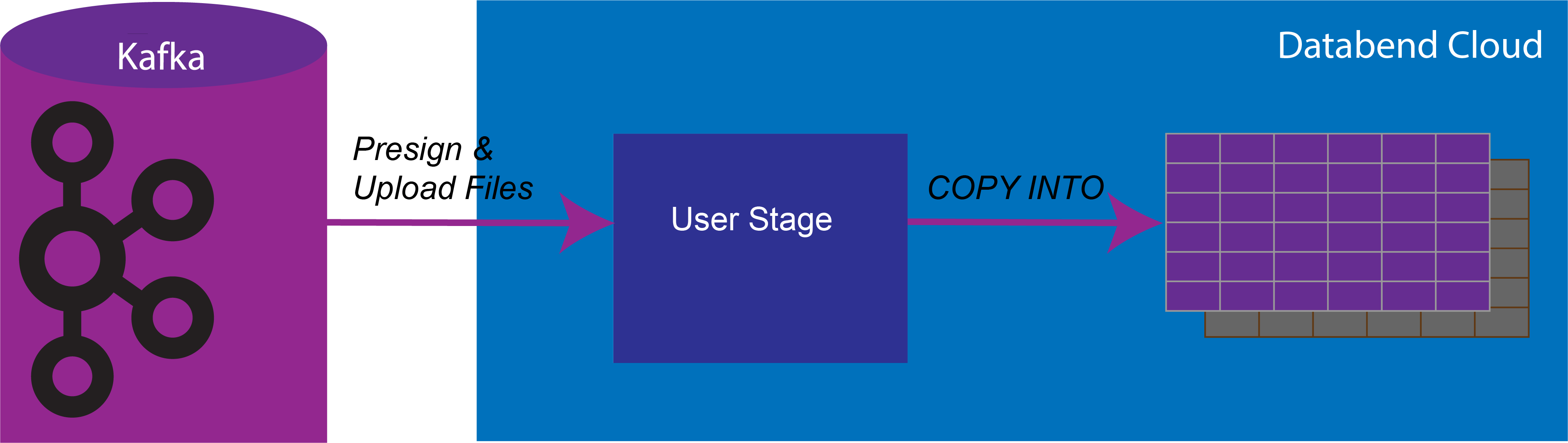
This post will guide you through the process of loading data from Kafka, a message queueing system, into Databend Cloud.
In this post:
- 1. Creating a Table in Databend Cloud
- 2. Obtaining a Connection String from Databend Cloud
- 3. Installing databend-py
- 4. Developing Your Program
- Useful Links
1. Creating a Table in Databend Cloud
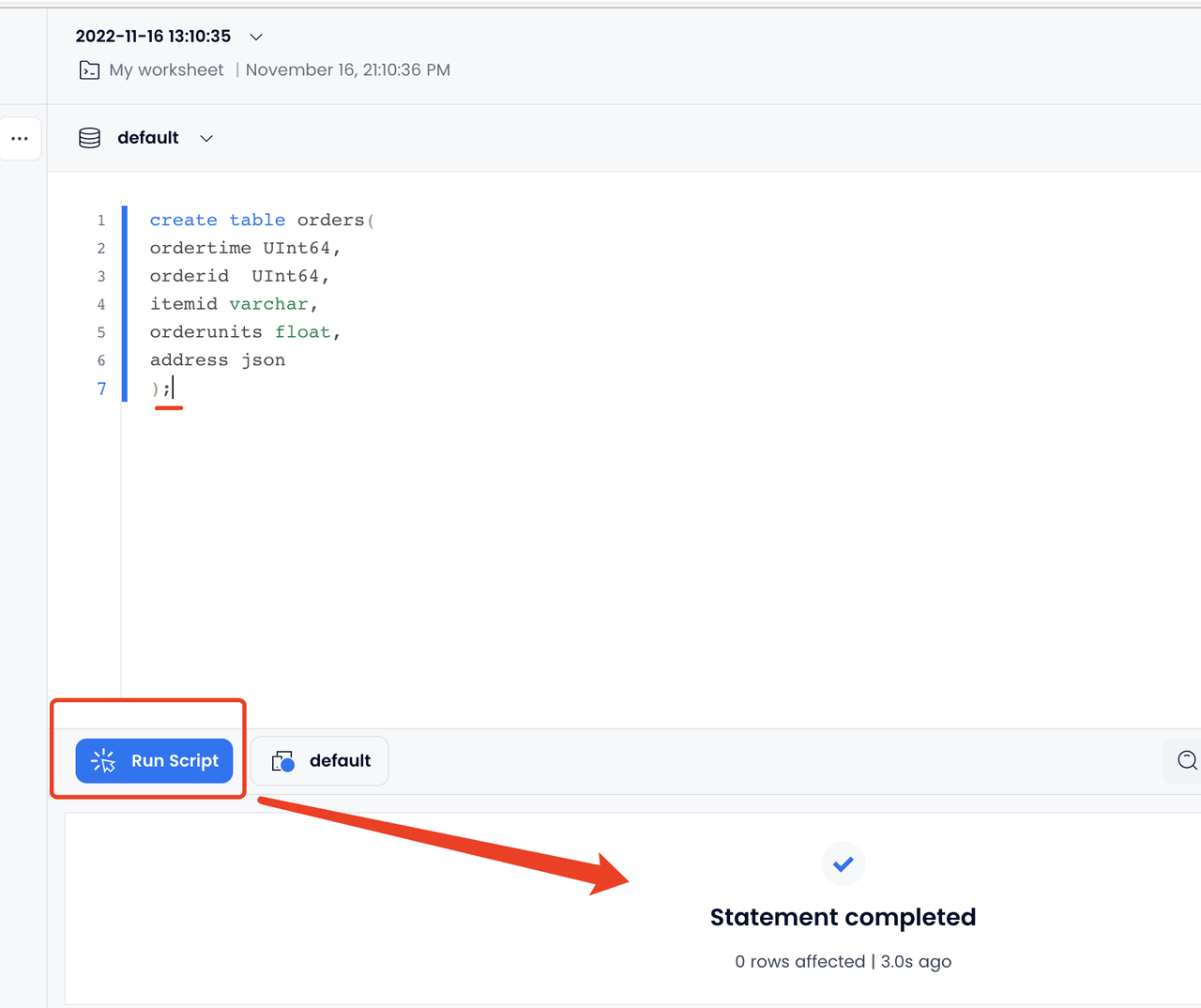
Sign in to Databend Cloud, and create a table (for example, using the following script) on Worksheets > New Worksheet.
create table orders(
ordertime UInt64,
orderid UInt64,
itemid varchar,
orderunits float,
address json
);
2. Obtaining a Connection String from Databend Cloud
- In Databend Cloud, select the Home tab, then click Connect.
- Click Reset DB password to generate a new password, then click on the generated password to copy and save it to a secure place.
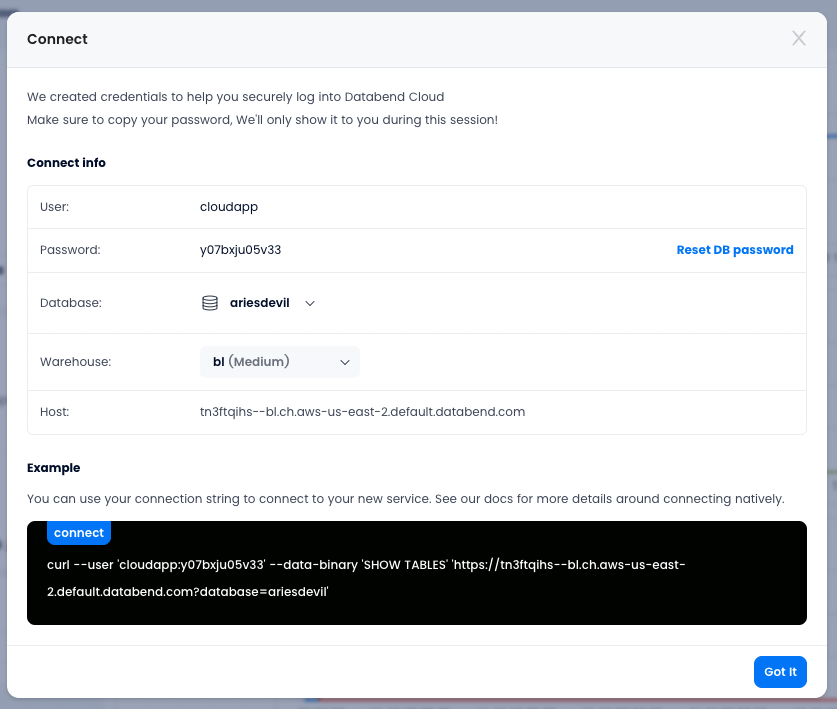
The connection string in the snapshot above provides the following information about the connection:
- host='tn3ftqihs--bl.ch.aws-us-east-2.default.databend.com',
- database="default",
- user="cloudapp",
- password=
"<your-password>"
3. Installing databend-py
databend-py is a Python SQL driver for Databend Cloud that provides a standard SQL interface for users to manipulate data in Databend Cloud.
To install databend-py:
pip install databend-py
pip install kafka-python
Test the connection string with the following code. Verify that it returns "1" without any errors.
from databend_py import Client
client = Client(
host='tn3ftqihs--bl.ch.aws-us-east-2.default.databend.com',
database="default",
user="cloudapp",
password="x")
print(client.execute("SELECT 1"))
4. Developing Your Program
4.1 Loading Data
Write code to perform the following tasks for data loading:
- To connect to Kafka, you need to install the dependency kafka-python.
Kafka information:
Topic: s3_topic
bootstrap_servers: 192.168.1.100:9092
For a Kafka cluster, separate multiple addresses by commas.
- Connect to a warehouse in Databend Cloud.
- Get data from Kafka.
- Get a presigned URL.
- Upload your file.
- Load data from the file with COPY INTO.
#!/usr/bin/env python3
from databend_py import Client
import os
import io
import requests
import time
from kafka import KafkaConsumer
consumer = KafkaConsumer('s3_topic', bootstrap_servers = '192.168.1.100:9092')
client = Client(
host='tn3ftqihs--bl.ch.aws-us-east-2.default.databend.com',
database="default",
user="cloudapp",
password="x")
def get_url(file_name):
sql="presign upload @~/%s"%(file_name)
_, row = client.execute(sql)
url = row[0][2]
return url
def upload_file(url,content):
response=requests.put(url, data=content)
def load_file(table_name, file_name):
copy_sql="copy into %s from @~ files=('%s') file_format=(type='ndjson') purge=true"%(table_name,file_name)
client.execute(copy_sql)
def get_table_num(table_name):
sql="select count(*) from %s"%(table_name)
_, row=client.execute(sql)
print(row[0][0])
i=0
c=b''
table_name='orders'
# you can increase this value to increase the throughput
step = 10000
for msg in consumer:
c = c+msg.value+b'\n'
i = i + 1
if i % step == 0 :
file_name='%d.json'%(i)
#print(file_name)
url = get_url(file_name)
#print(url)
content = io.BytesIO(c)
r = upload_file(url,content)
load_file(table_name,file_name)
get_table_num(table_name)
c= b''
A demo program for generating the test data:
./bin/ksql-datagen quickstart=orders format=json topic=s3_topic maxInterval=10
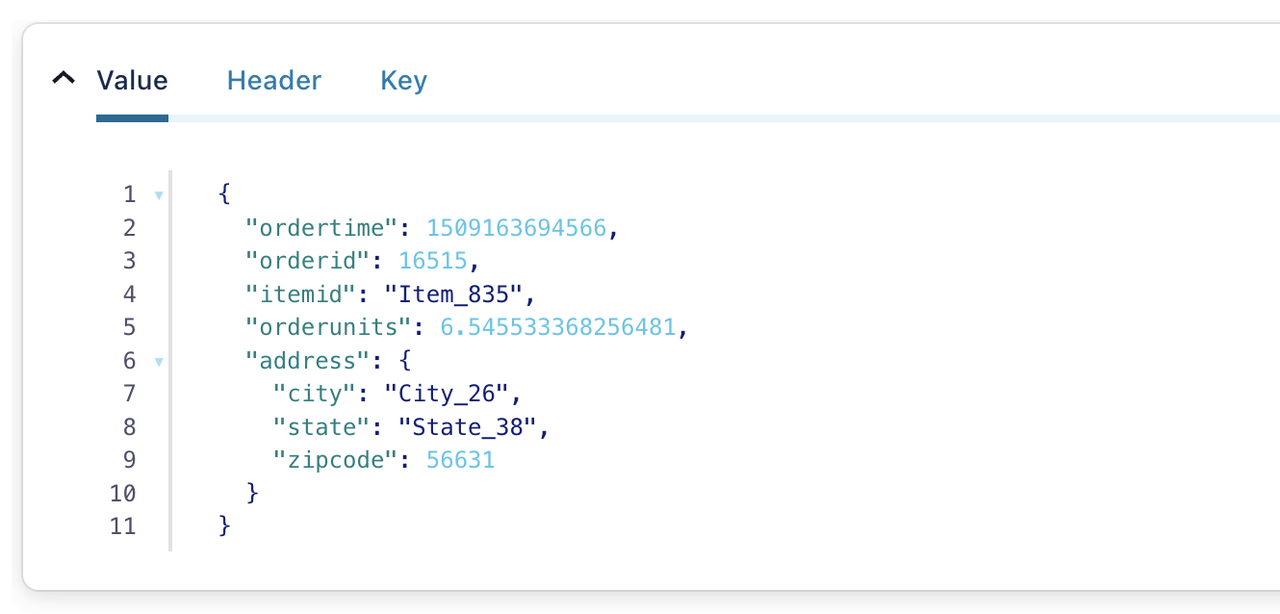
The following is an example of data written to the Kafka topic. For the supported data formats, see https://docs.databend.cn/guides/load-data/.
4.2 Querying Data
#!/usr/bin/env python3
from databend_py import Client
client = Client(
host='tn3ftqihs--bl.ch.aws-us-east-2.default.databend.com',
database="default",
user="cloudapp",
password="x")
sql="select * from orders limit 1"
_, row = client.execute(sql)
print(row)
Useful Links
- Databend pesign: https://docs.databend.cn/sql/sql-commands/ddl/stage/presign
- Load data with COPY INTO: https://docs.databend.cn/sql/sql-commands/dml/dml-copy-into-table
- databend-py https://github.com/databendcloud/databend-py
- Load data: https://docs.databend.cn/guides/load-data/
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


