




数据是洞察力的基石,越来越多的企业开始建设以数据资产为中心的存储和分析一体化方案,这要求 Data Infra 架构能够提供可扩展、灵活且统一的数据工作流。现代数据湖架构同时兼顾数据湖的可扩展性和数据仓库的性能,满足对大规模数据处理的需求,并应对数据的复杂性挑战。本文将介绍如何围绕 Databend 生态系统构建现代数据湖,并且提供可一个简单的示例,展示如何结合 Apache DolphinScheduler 和 DataX 等工具,构建一个高效、可靠的现代数据湖工作流。
基于 Databend 的现代数据湖架构概述
现代数据湖的典型特征之一是能够灵活和高效地利用云上的基础设施,并且使用对象存储作为数据的存储方案。作为一款云原生、湖仓一体的数据管理系统,Databend 基于对象存储进行设计,存算分离的架构进一步匹配云上计算资源灵活调度的模式,现代 MPP 架构和充分的优化能够充分释放算力。
开放数据格式(如 Parquet、ORC)与表格式(如 Apache Iceberg 和 Delta Lake)的兴起,使得存储方案可以从原有存储方案自然迁移到对象存储上,并且可以进一步构建包括 Time Travel 和数据分支等在传统数仓中鲜有实现的高级特性。Databend 充分利用开源开放的数据生态,除了支持多种结构化和半结构化数据格式之外,还允许用户以 Catalog 和 表引擎形式挂载多种数据源,丰富的数据处理技术栈,使得围绕 Databend 构建的现代数据湖可以从容应对数据量和复杂性挑战。
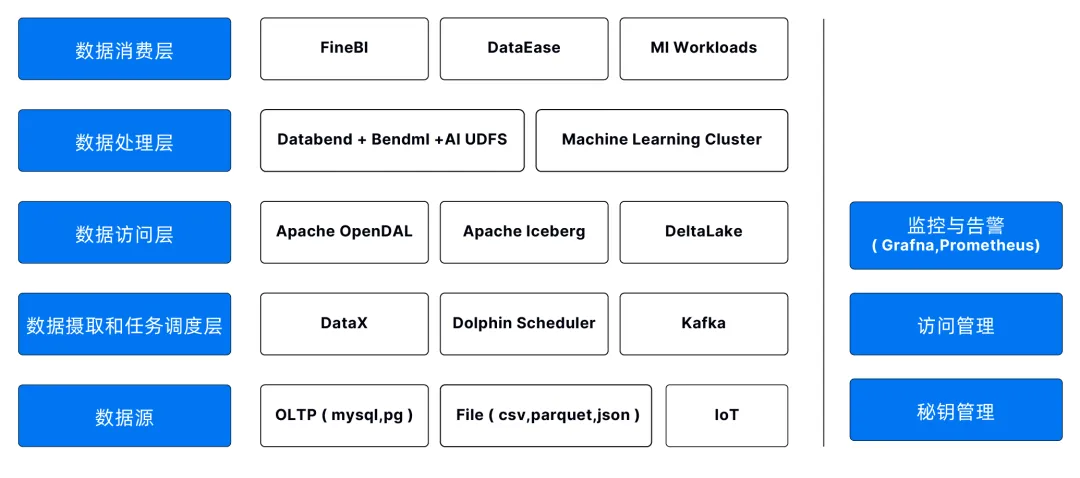
接下来我们尝试从一个分层模型上观察围绕 Databend 生态所构建的现代数据湖架构:
-
数据消费层:包含用于数据可视化和商业分析的工具,如 FineBI 和 DataEase 等。此外,这一层也会包含需要访问数据湖结果的应用程序和机器学习工作负载。
-
数据处理层:Databend 提供湖仓一体,可以弹性扩缩容的高性能计算集群,满足数据转换和查询分析的复杂需求,够高效处理大规模数据查询和分析任务。Databend 是一种关系型数据管理系统,同时兼具向量支持和处理能力,也能为上层的 MLOps 工具和生成式 AI 提供支持。此外,Databend 还支持丰富的 UDFs 能力,用户可以根据业务实际场景构建解决方案。
-
数据访问层:尽管对象存储是现代数据湖的主要存储服务,但是实际的存储架构可能更加复杂,这是由于现代数据湖需要兼顾不同来源和历史的数据。
- Apache OpenDAL 提供了统一的数据访问层,使得可以在同一个模型下管理位于对象存储、HDFS、文件系统和互联网上的数据集。
- 由于开放表格式技术在现代数据湖架构中的广泛应用,这一层还需要包含用于挂载到处理层的一些数据服务。Databend 现已支持 Apache Hive、Apache Iceberg 和 Delta Lake,能够有效地访问位于不同数据湖中的数据。
-
数据摄取和任务调度层:包含用于管理和调度各种数据处理任务的工具,并为数据的摄入提供支持。
- Apache DolphinScheduler 是一个分布式和可扩展的开源工作流协调平台,提供可视化的 DAG 工作流管理和调度数据任务,能够在不影响工作流模板的情况下,支持工作流实例的修改、回滚和重新运行。
- DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库 (MySQL、Oracle 等)、HDFS、Hive、ODPS、HBase、FTP 等各种异构数据源之间稳定高效的数据同步功能。
- 借助 Flink CDC,可以实时捕获并同步源数据库的变更数据。
-
数据源:尽管数据源并不属于现代数据湖架构的一部分,但支持复杂多样的结构化和半结构化数据已经是现代数据湖必须具备的能力。
此外,考虑到现代数据湖架构对监控和告警系统的需要,可以结合 Grafana 和 Prometheus,对整个数据湖资源进行实时监控和告警,比如查询响应时间、并发连接数、慢查询日志等。
实践经验与 最佳实践
数据摄取与处理
- 增量更新与全量更新结合: 对于数据量较大的表,采用增量更新策略可以显著减少数据处理时间。只有在必要时才进行全量更新。
- 数据质量监控: 建立数据质量监控机制,及时发现并处理数据异常。可以使用 Apache DolphinScheduler 定期运行数据校验任务,确保数据的一致性和完整性。
性能优化
- 集群配置调整:根据实际业务需求动态调整 Databend 集群资源配置,以平衡性能和成本。也可以结合 Databend Cloud 实现实时混合云架构,进一步提高资源调度能力。
- 缓存:利用 Databend 的多层缓存机制,减少重复查询对系统性能的影响。
- 聚类 键和聚合索引:通过精心设计聚类键,并引入聚合索引,可以有效提高查询性能。
- 定期进行 Compact 和 Recluster:优化存储空间的使用,提升查询效率。这些操作会重组数据,从而减少碎片化,提升整体性能。
安全与合规
- 访问控制:充分利用 Databend 的所有权机制,为不同角色和用户配置细粒度的访问控制策略,确保只有经过授权的用户才能访问敏感数据。
- 存储加密:利用 Databend 的存储加密能力,可以有效保护数据的机密性和完整性。
- 日志审计:启用日志审计功能,记录所有数据访问和操作日志,以便追踪和分析潜在的安全事件。
监控与告警
- 系统监控:实时监控整个数据湖的运行状态,包括 CPU、内存、磁盘 I/O 等关键指标。Databend 也提供基于 Grafana 和 Prometheus 的监控方案。
- 告警设置:配置合理的告警规则,当系统出现异常时,及时通知运维人员进行处理。
- 性能分析:通过 Databend 内置的性能剖析能力和第三方性能分析工具,定期分析系统瓶颈,进一步保障数据湖平稳运行。
Workshop: 使用 Databend 和 Apache DolphinScheduler 构建现代数据湖 工作流
在接下来的 Workshop 中,我们将会提供一个简单的示例,帮助你了解如何结合 Databend、Apache DolphinScheduler 和 DataX 构建一个简单的现代数据湖工作流,实现 MySQL 到 Databend 的异构数据库合并。
准备数据并建表
首先在 MySQL 中创建相关的表结构和数据。
MySQL> create database db;
MySQL> create table db.tb01(id int, d double, t TIMESTAMP, col1 varchar(10));
MySQL> insert into db.tb01 values(1, 3.1,now(), 'test1'), (1, 4.1,now(), 'test2'), (1, 4.1,now(), 'test2');
在 Databend 中建立对应的表结构。(将 MySQL 的 db.tb01 数据迁移至 Databend 的 migrate_db.tb01)
databend> create database migrate_db;
databend> create table migrate_db.tb01(id int null, d double null, t TIMESTAMP null, col1 varchar(10) null);
准备 DataX
根据文档准备 DataX 可执行环境,这里使用预先编译好的二进制进行。
也可以按照下面的方式自行编译,编译好的 DataX 将位于
{DataX_source_code_home}/target/datax/datax/
git clone git@github.com:alibaba/DataX.git
cd DataX
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
启动 dolphinscheduler
启动之前先设置 Datax 依赖的环境变量:
export DATAX_HOME=/your/path/to/datax
export PYTHON_HOME=/your/path/to/python3
参考文档启动 DolphinScheduler Standalone 快速开发模式,前后端均启动成功后访问
http://localhost:12345/dolphinscheduler/ui
admin/dolphinscheduler123
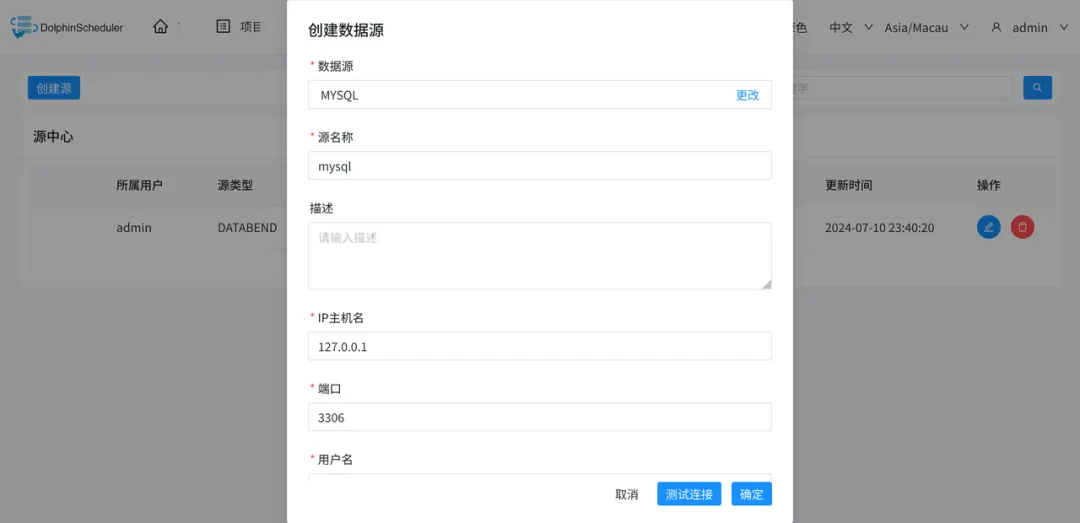
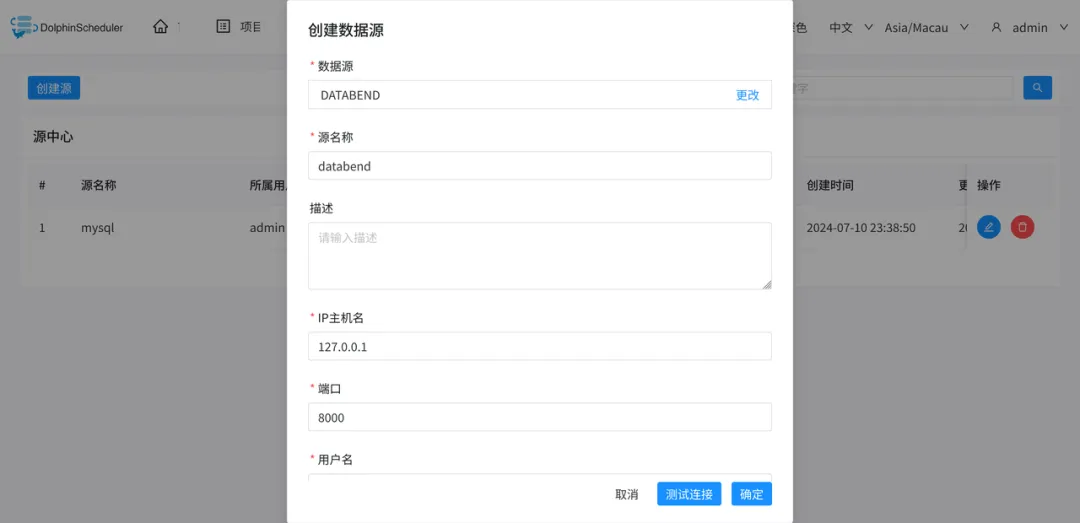
创建 数据源
点击
源中心->创建源
MySQL
Databend
创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击“创建工作流”按钮,进入 DAG 编辑页面;
- 拖动数据集成工具栏的
- 任务节点到画板中。
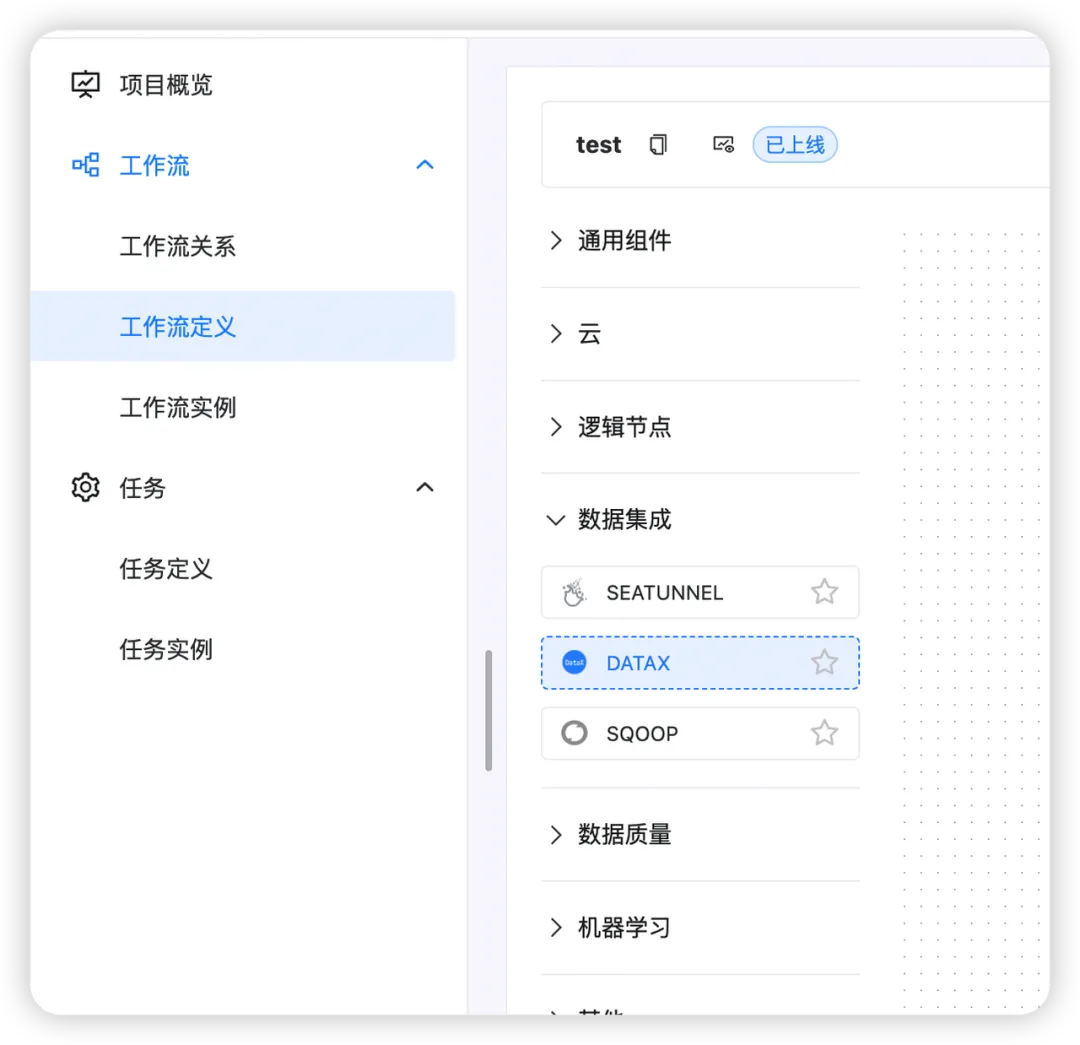
填写 Datax 任务模板
选择
自定义模板
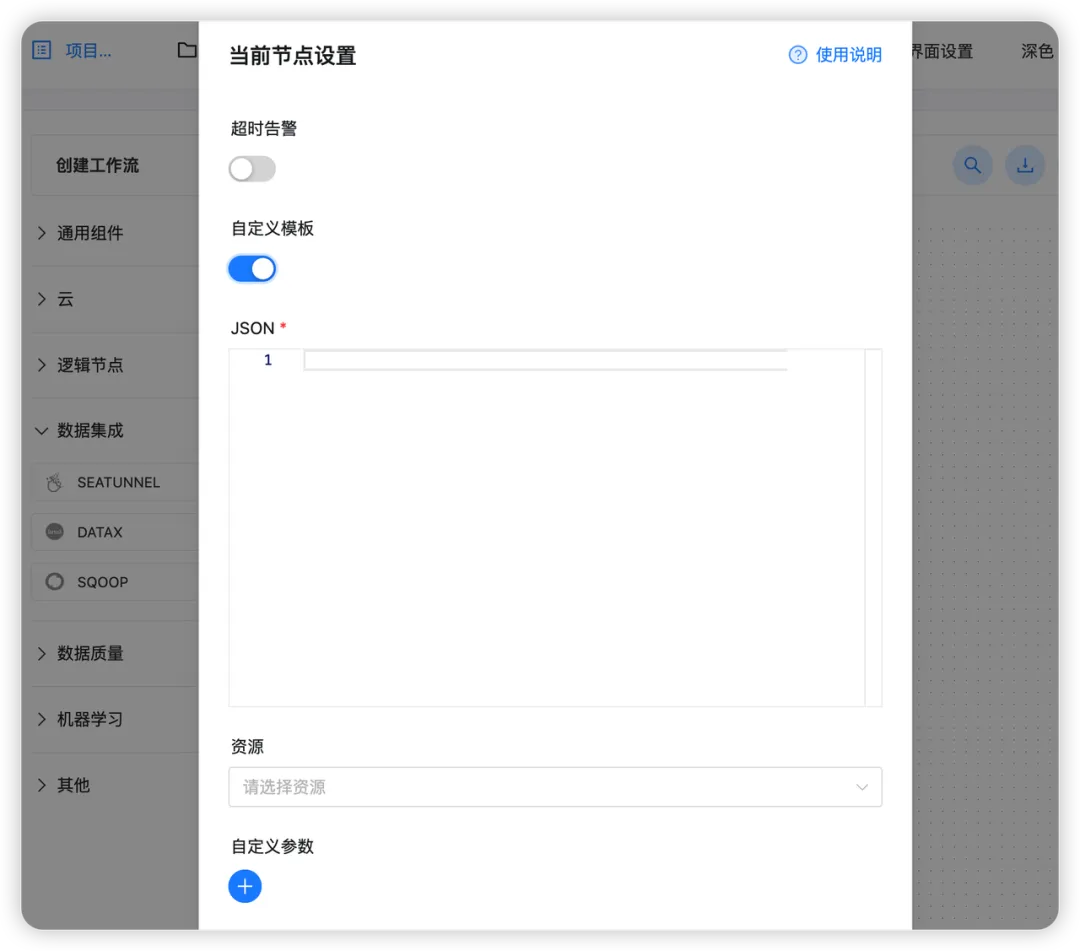
将下面的 json 配置填入:
{
"job": {
"content": [
{
"reader": {
"name": "MySQLreader",
"parameter": {
"username": "root",
"password": "password",
"column": [
"id", "d", "t", "col1"
],
"connection": [
{
"jdbcUrl": [
"jdbc:MySQL://127.0.0.1:3306/db"
],
"driver": "com.MySQL.cj.jdbc.Driver",
"table": [
"tb01"
]
}
]
}
},
"writer": {
"name": "databendwriter",
"parameter": {
"username": "root",
"password": "",
"column": [
"id", "d", "t", "col1"
],
"batchSize":1000000,
"batchByteSize": 1000000000,
"preSql": [
],
"postSql": [
],
"connection": [
{
"jdbcUrl": "jdbc:databend://127.0.0.1:8000/migrate_db",
"table": [
"tb01"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": 10,
"byte": -1,
"record": -1,
"batchSize": 1000000
}
}
}
}
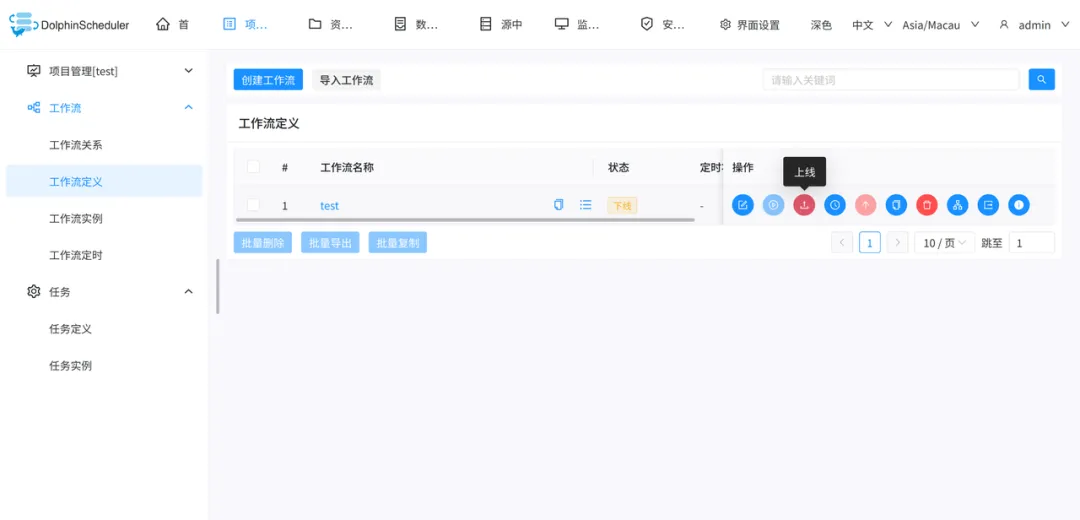
任务上线
点击
工作流定义
上线
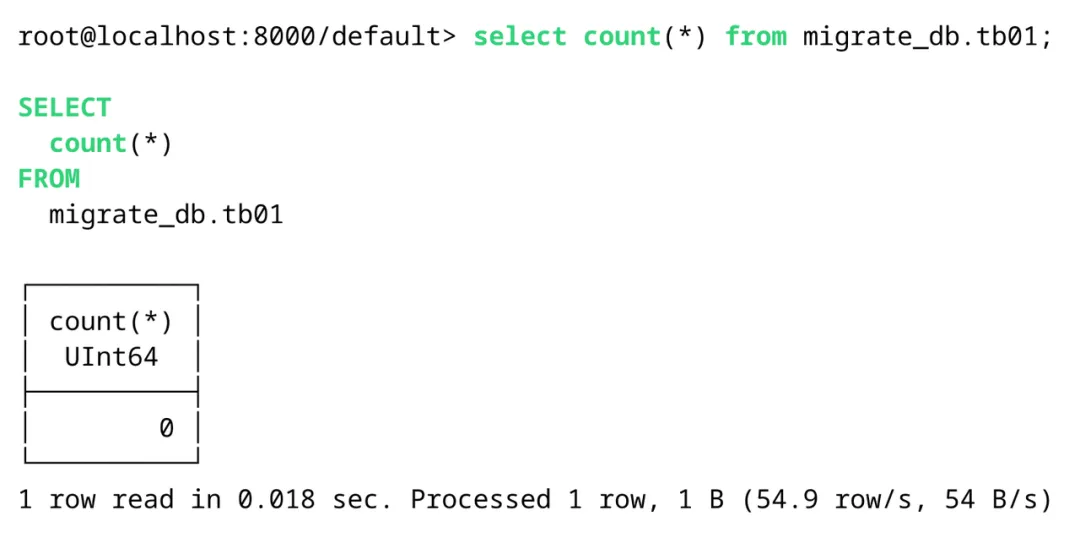
任务执行
执行 Datax 任务之前先检查一下目标表的情况:
点击
运行
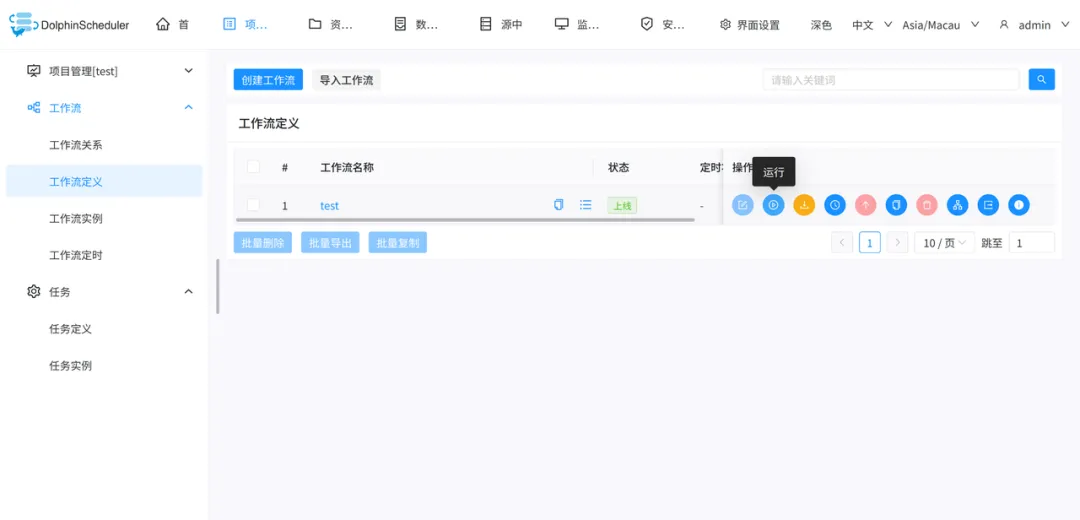
任务开始后可以到
任务实例
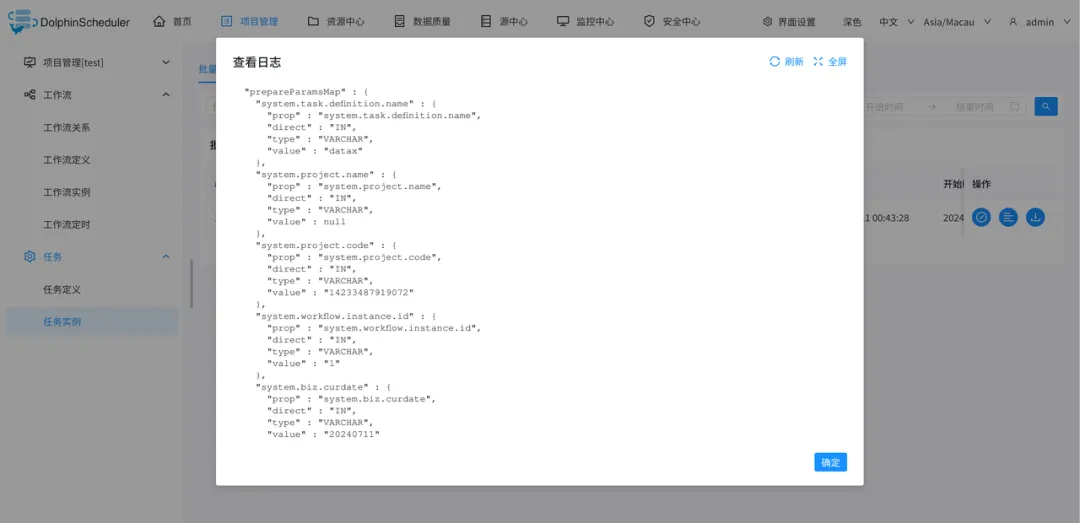
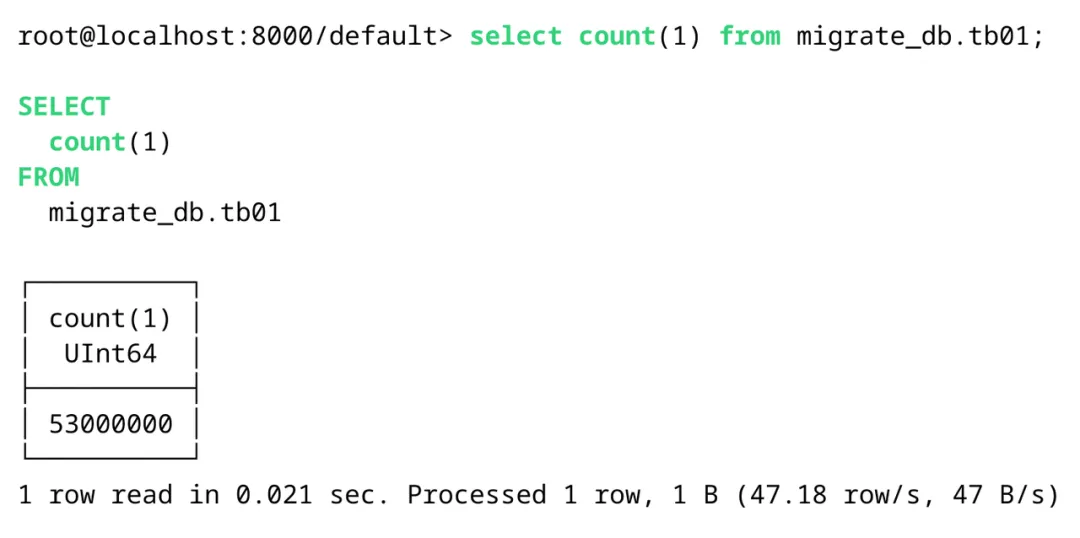
可以看到运行一段时间后,数据已经从 MySQL 同步到 Databend,数据可以进行进一步查询分析或者供上层工作负载消费。
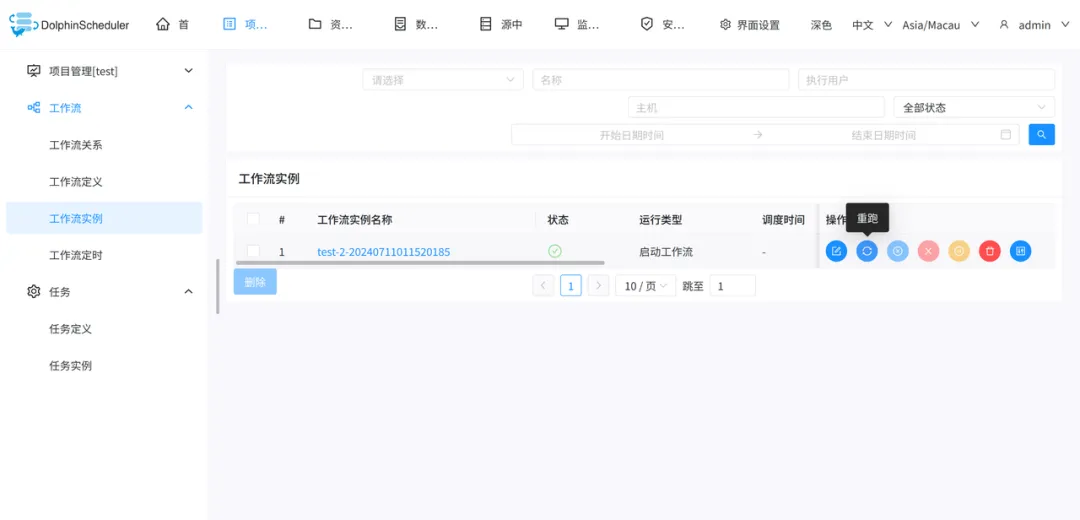
控制工作流
在
工作流实例
总结
利用 Databend 及其生态系统可以构建可扩展、灵活和统一的现代数据湖,结合 Apache DolphinScheduler 和 DataX 等工具,可以实施高效、可靠的现代数据湖工作流。这种架构不仅提高了数据处理的效率,还增强了系统的稳定性和可监控性,为企业提供强大的数据洞见与决策支持能力。
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


