




各位社区小伙伴们,Databend 于 2023 年 6 月 29 日迎来了 v1.2.0 版本的正式发布!相较于 v1.1.0 版本,开发者们一共新增了 600 次 commit,涉及 3083 个文件变更,约 17 万 行代码修改。感谢各位社区伙伴的参与,以及每一个让 Databend 变得更好的你!
在 v1.2.0 版本中,Databend 新增了 BITMAP 数据类型 、 使用列号直接查询 CSV/TSV/NDJSON 文件 、AI Functions 等特性,并 设计并实现全新哈希表 大幅提升 Join 的性能。这个版本的发布使得 Databend 更接近实现 LakeHouse 的愿景,能够直接读取和分析储存在对象存储上的 CSV/TSV/NDJSON/Parquet 等格式文件,你也可以在 Databend 内部对这些文件进行 ETL 操作,从而做一些更高性能的 OLAP 分析。
同时,Databend 也设计并实现了 计算列 、VACUUM TABLE 和 Serveless Background Service 等企业级特性,感兴趣的小伙伴可以联系 Databend 团队 了解升级信息,或者访问 Databend Cloud 即时体验。
Databend x 内核
Databend 重要新特性速览,遇到更贴近你心意的 Databend。
数据类型:BITMAP
BITMAP
Databend 新增对
BITMAP
BITMAP
Databend 中的
BITMAP
RoaringTreemap
SELECT user_id, bitmap_count(page_visits) AS total_visits
FROM user_visits
+--------+------------+
|user_id |total_visits|
+--------+------------+
| 1| 4|
| 2| 3|
| 3| 4|
+--------+------------+
如果你想要了解更多信息,请查看下面列出的资源。
- Docs | Data Types - BITMAP
- Docs | SQL Functions - Bitmap Functions
- Paper | Consistently faster and smaller compressed bitmaps with Roaring
使用列号直接查询 CSV/TSV/NDJSON 文件
要想查询 CSV/TSV/NDJSON 这类没有 schema 的文件,以前需要将其加载到表中再进行查询。但是有时候用户事先并不了解文件的具体情况(例如 CSV 文件有多少列),或者只是想做临时的查询。
为此,Databend 引入了列号(column position), 使用
$N
N
String
$1
将这一能力与 COPY 语句结合使用,可以实现按需加载部分列,并在加载同时使用函数进行数据转换。
SELECT $1 FROM @my_stage (FILE_FORMAT=>'ndjson')
COPY INTO my_table FROM (SELECT TRIM($2) SELECT @my_stage t) FILE_FORMAT = (type = CSV)
如果你想要了解更多信息,请查看下面列出的资源。
设计并实现全新哈希表以提高 Hash Join 性能
在过去,Databend 的哈希表是为了满足聚合算子的需求而专门设计的,为了进一步提高 Hash Join 的性能,我们着手设计并实现了一种专为 Hash Join 优化的全新哈希表,通过并行化的设计,使 Databend 能够充分利用计算资源,同时在内存控制方面也变得更为精准,避免了不必要的内存开销,显著提高了 Hash Join 的性能。
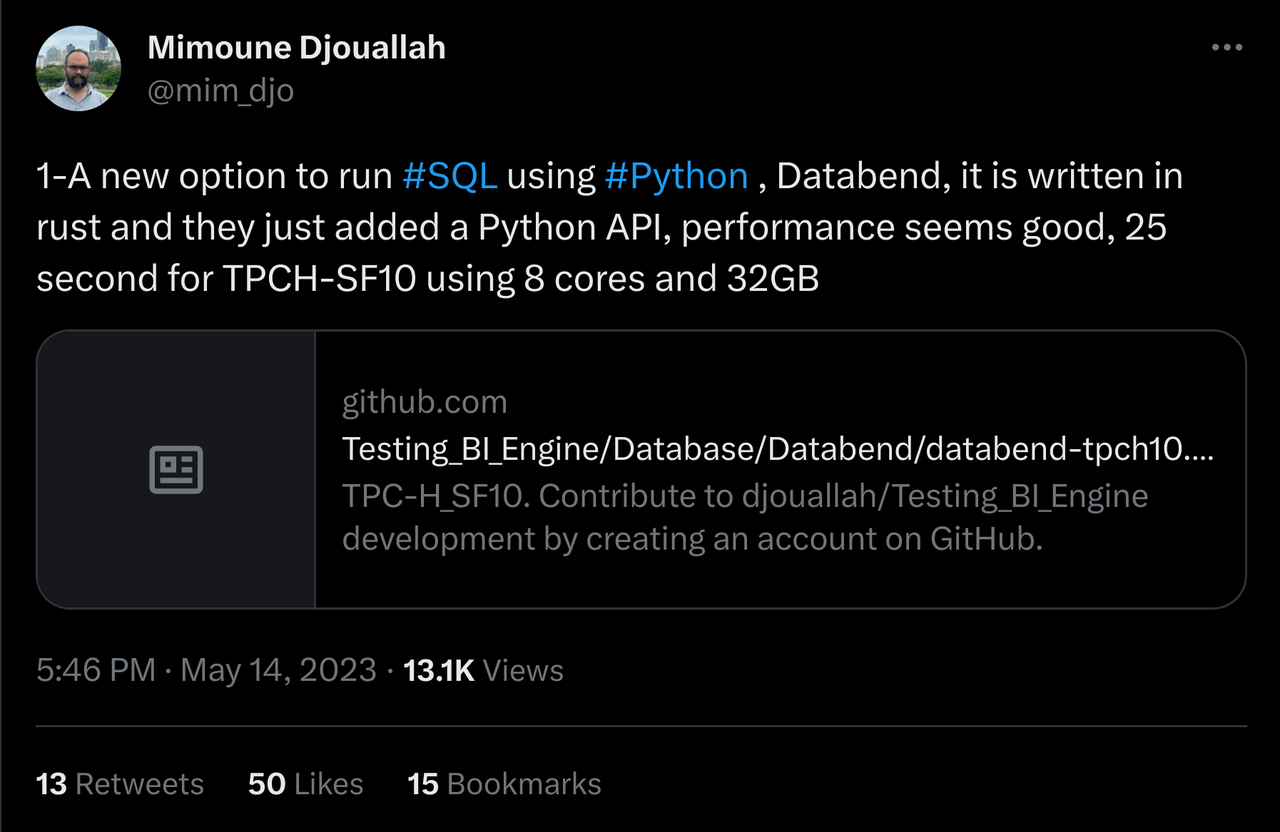
商业智能分析师 Mimoune Djouallah 评论称:Databend 性能出色,在 8 核和 32GB 内存的条件下,运行 TPCH-SF10 只需要 25 秒。他甚至撰写了一篇题为《Databend and the rise of Data warehouse as a code》的博客文章。
如果你想要了解更多信息,请查看下面列出的资源。
- Data Infra #12 | Databend's New Hash Table for Hash Join
- PR #11140 | feat(query): new hash table and parallel finalize for hash join
AI Functions
Databend 在 v1.2.0 版本引入了强大的 AI 功能,实现了 Data 与 AI 的无缝融合,我们可以通过 SQL 来实现:
- 自然语言生成 SQL
- Embedding 向量化并存储
- 相似度计算
- 文本生成
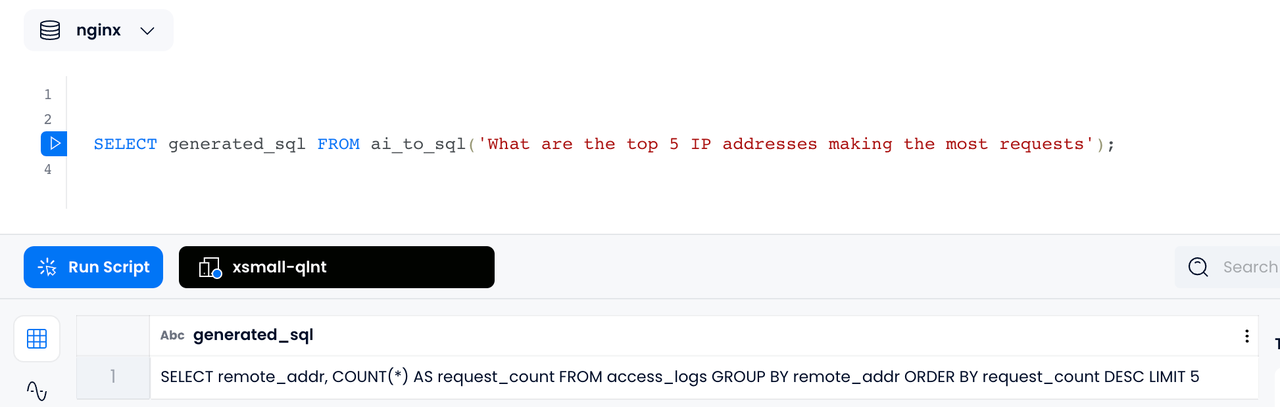
自然语言生成 SQL
比如,如果你在一个 nginx log 的数据库中提问:"What are the top 5 IP addresses making the most requests",运用 Databend 的
AI_TO_SQL
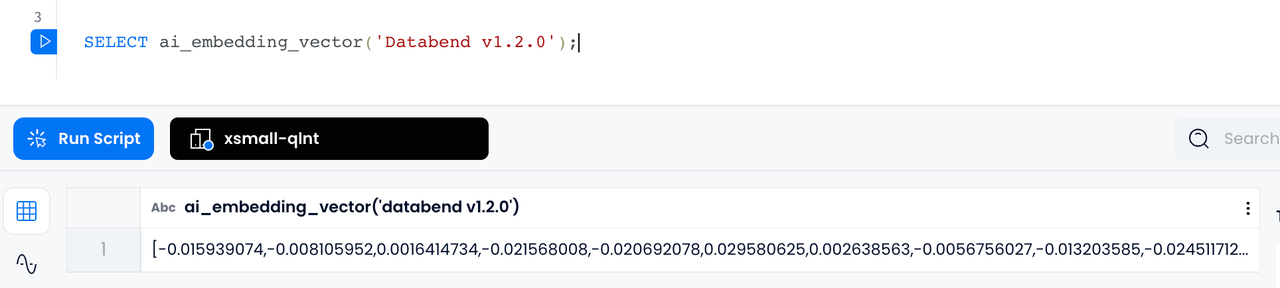
Embedding 向量化
借助 Databend 的
AI_EMBEDDING_VECTOR
ARRAY
相似度计算
在向量化表示下,可以计算两个词语、句子或文档的相似度。 例如,假设我们有 "dog" 和 "puppy" 两个词语(也可以是句子),我们首先将它们各自转化为向量 v1 和 v2,然后使用余弦相似度来计算它们的相似度。
cos_sim = dot(v1, v2) / (norm(v1) * norm(v2))
Databend 中的
COSINE_DISTANCE

文本生成
文本生成在很多场景下非常有用,现在你可以在 SQL 中使用
AI_TEXT_COMPLETION

目前,我们已经利用以上 Data + AI 能力,对 https://docs.databend.cn 的所有文档进行了 Embedding 处理,并将其存储到 Databend 中,构建了一个智能问答网站:https://ask.databend.com。 在这个网站上,你可以提问关于 Databend 的任何问题。
Databend 企业级特性
全新企业级特性上线啦!了解 Databend 如何推动更具价值的数据分析服务。
计算列
计算列(Computed Columns)是一种通过表达式从其他列计算生成数据的列,使用计算列可以将表达式的数据存储下来加快查询速度,同时可以简化一些复杂的查询的表达式。计算列包括存储(STORED)和虚拟(VIRTUAL)两种类型。
- 存储计算列在每次插入或更新时生成数据并存储在磁盘,在查询时不需要重复计算,可以更快的读取数据。
- 虚拟计算列不存储数据,不占用额外的空间,在每次查询时实时进行计算。
计算列对读取 JSON 内部字段的数据特别有用,通过将常用的内部字段定义为计算列可以大大减少每次查询过程中提取 JSON 数据的耗时操作。例如:
CREATE TABLE student (
profile variant,
id int64 null as (profile['id']::int64) stored,
name string null as (profile['name']::string) stored
);
INSERT INTO student VALUES ('{"id":1, "name":"Jim", "age":20}'),('{"id":2, "name":"David", "age": 21}');
SELECT id, name FROM student;
+------+-------+
| id | name |
+------+-------+
| 1 | Jim |
| 2 | David |
+------+-------+
如果你想要了解更多信息,请查看下面列出的资源。
VACUUM TABLE
VACUUM TABLE
- 与表相关的快照及其关联的 segments 和 blocks。
- 孤立文件。在 Databend 中,孤立文件指不再与该表关联的快照、segments 和 blocks。孤立文件可能由各种操作和错误生成,例如在数据备份和还原期间,并且随着时间的推移会占用宝贵的磁盘空间并降低系统性能。
如果你想要了解更多信息,请查看下面列出的资源。
Serverless Background Service
Databend 的内置存储引擎
FuseTable
为了自动化执行这一过程需要使用不同的驱动,增加了基础设施的复杂性。而且必须部署和维护其他服务来触发驱动事件。为简化这一过程,Databend 设计并实现了 Serverless Background Service ,能自动发现数据写入之后需要压缩、重排序、清理的表,无需其他服务,也无需用户手动操作,自动触发对应表的维护工作,降低了用户维护的负担,提升了表查询的性能,也降低了数据在对象存储中的成本。
Databend x 生态
Databend 的生态版图得到了进一步的完善。是时候将 Databend 引入你的数据洞见工作流啦!
databend 的 Python 绑定
Databend 现在提供 Python 绑定,为在 Python 中执行 SQL 查询提供了新选择。该绑定内置 Databend,无需部署实例即可使用。
pip install databend
从 databend 导入
SessionContext
from databend import SessionContext
ctx = SessionContext()
df = ctx.sql("select number, number + 1, number::String as number_p_1 from numbers(8)")
结果 DataFrame 可以使用
to_py_arrow()
to_pandas()
df.to_pandas() # Or, df.to_py_arrow()
现在行动起来,将 Databend 集成到你的数据科学工作流中。
BendSQL - Databend 原生命令行工具
BendSQL 是一款专为 Databend 设计的原生命令行工具,现在已经用 Rust 语言重写,并且同时支持 REST API 和 Flight SQL 协议。
使用 BendSQL,你可以轻松高效地管理 Databend 中的数据库、表和数据,并轻松执行各种查询和运算。
bendsql> select avg(number) from numbers(10);
SELECT
avg(number)
FROM
numbers(10);
┌───────────────────┐
│ avg(number) │
│ Nullable(Float64) │
├───────────────────┤
│ 4.5 │
└───────────────────┘
1 row in 0.259 sec. Processed 10 rows, 10B (38.59 rows/s, 308B/s)
我们期待与你分享更多关于 BendSQL 的更新!欢迎试用并给我们反馈。
数据集成和 BI 服务
Apache DolphinScheduler
Apache DolphinScheduler 是一个分布式和可扩展的开源工作流协调平台,具有强大的 DAG 可视化界面。支持 30+ 的任务类型,包括像 Flink SQL、DataX、HiveCli 等。能够高并发、高吞吐量、低延迟和稳定地执行百万个量级任务,可以根据计划时间(特殊日期范围或特殊的日期列表)批量执行任务,而且在不影响工作流模板的情况下,工作流实例支持修改、回滚和重新运行。

DolphinScheduler 现已支持 Databend 数据源,可以使用 DolphinScheduler 管理 DataX 任务实现从 MySQL 到 Databend 异构数据库数据同步。
Apache Flink CDC
Apache Flink CDC(Change Data Capture)是指 Apache Flink 使用基于 SQL 的查询从各种来源捕获和处理实时数据更改的能力。CDC 允许监视和捕获数据库或流系统中发生的数据修改(插入、更新和删除),并对这些更改进行实时响应。
Databend 现在提供 Flink SQL Connector,可以将 Flink 的流处理能力与 Databend 集成。通过对连接器进行配置,可以以流的形式从各种数据库中捕获数据更改,并将其载入到 Databend 中以进行实时处理和分析。
如果你想要了解更多信息,请查看下面列出的资源。
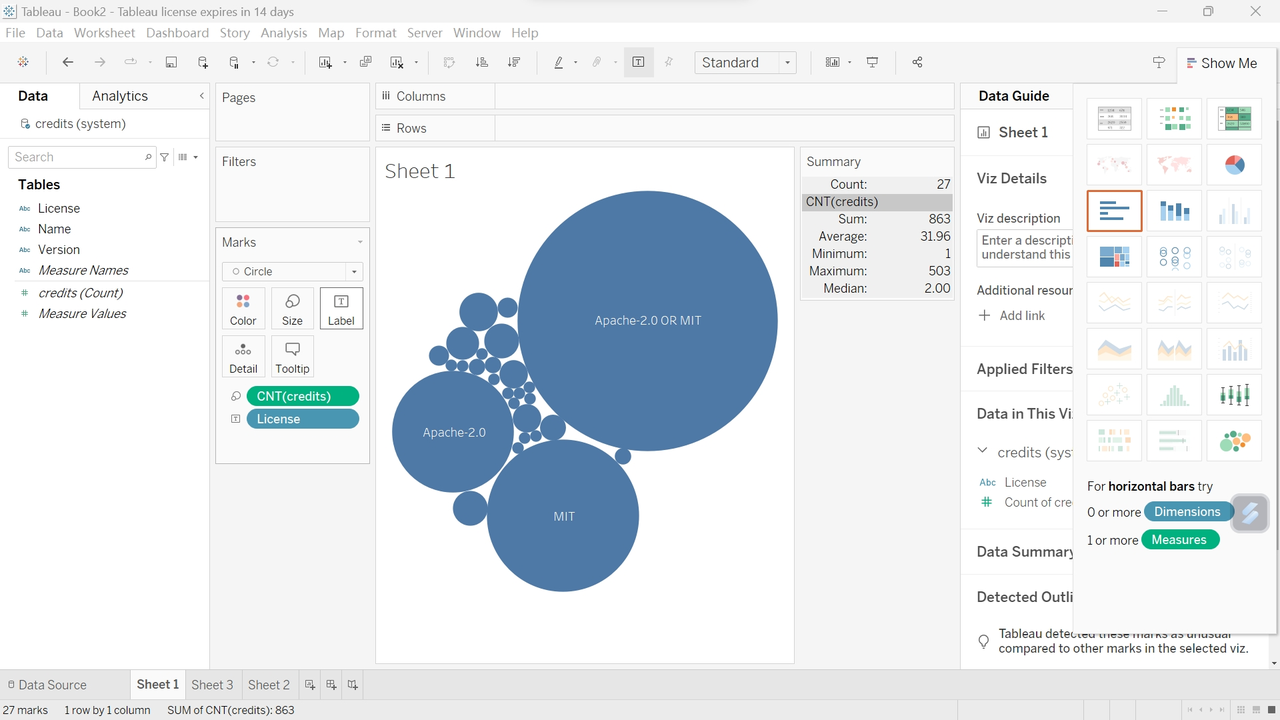
Tableau
Tableau 是一款流行的数据可视化和业务智能工具。它提供了直观、交互式的方式来探索、分析和呈现数据,帮助用户更好地理解数据的意义和洞察。
databend-jdbc
如果你想要了解更多信息,请查看下面列出的资源。
下载使用
如果你对我们新版本功能感兴趣,欢迎访问 https://github.com/databendlabs/databend/releases/tag/v1.2.0-nightly 页面查看全部的 changelog 或者下载 release 体验。
如果你还在使用旧版本的 Databend,我们推荐升级到最新版本,升级过程请参考:
https://docs.databend.cn/doc/operations/upgrade
意见反馈
如果您遇到任何使用上的问题,欢迎随时通过 GitHub issue 或社区用户群中提建议
GitHub: https://github.com/databendlabs/databend/
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


