




由「3306π」社区主办,「Databend」参与协办的「数据库朋友圈」活动于 9 月 16 日在北京 360 大厦成功举办!该活动汇集了数据库领域的资深专家和企业家,共同探讨数据库技术变革。
下午,Databend Labs 联合创始人张雁飞作为「Serverless 数仓技术与挑战」专题的演讲嘉宾进行了分享。
主题: 「Serverless 数仓技术与挑战」
演讲嘉宾: 张雁飞
嘉宾介绍: Databend Labs 联合创始人。前青云数据库团队负责人、开源 Databend 项目主要负责人。
演讲大纲: 传统数仓在扩展性、成本和管理等方面具有局限性。在本次分享中,我们将介绍一种新型的 Serverless 数仓技术,这种技术不仅能够解决传统数仓的痛点,还能显著提升性能并降低成本。此外,我们还将讨论 Serverless 数仓所面临的技术挑战。
- 传统数仓的局限性
- 理想的 Serverless 数仓架构
- 如何实现 Serverless 数仓以及有哪些挑战
以下为本次演讲的精彩内容:
当今(2023)大数据分析新问题
大数据分析面临的新问题
-
近 5 年生产了 ~90% 数据
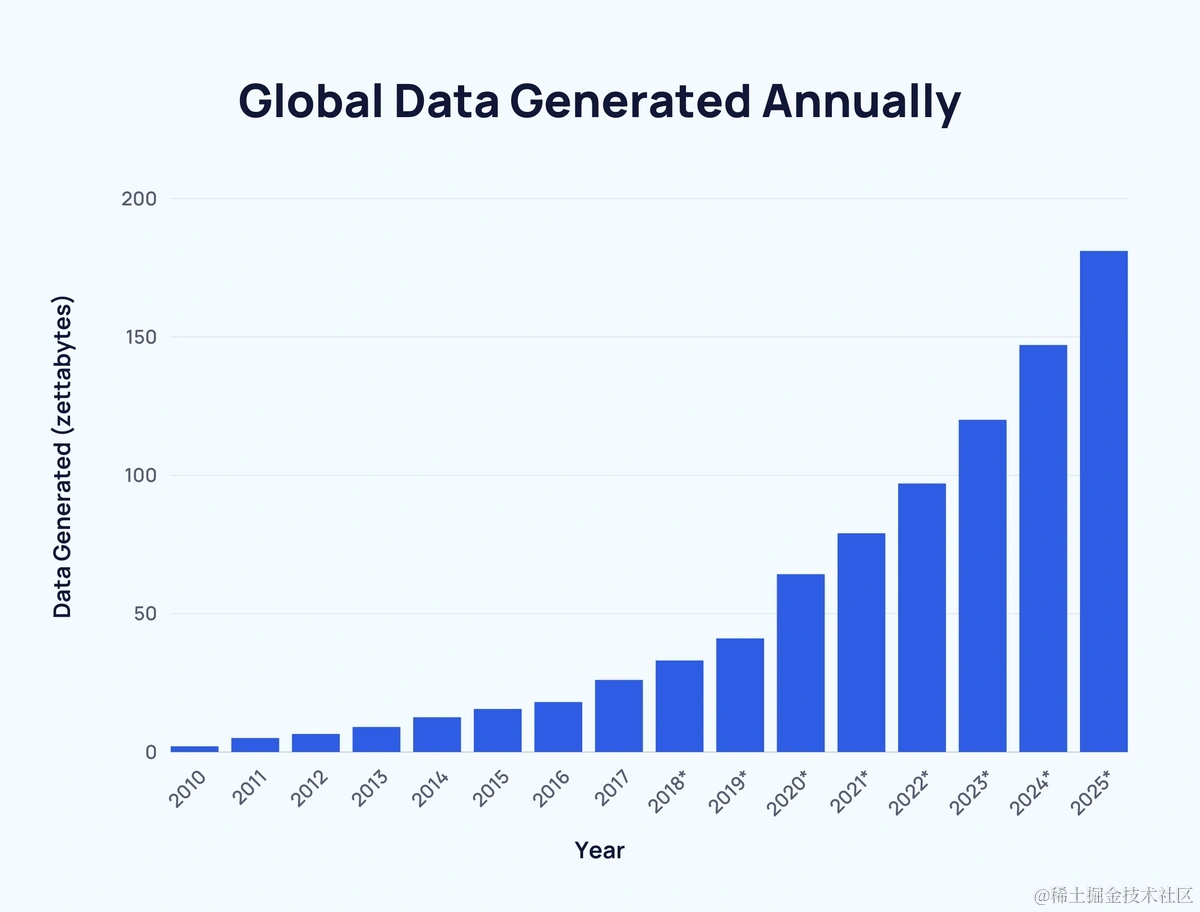
- 根据 IDC 的统计和预测,近 5 年来产生了大约 90% 的数据。这里用的单位是 zttabytes(ZB),1024PB = 1EB,1024EB = 1ZB 是一个非常庞大的数字。过去的大数据架构难以适应当下的数据规模,亟需变更,怎么样才能做到弹性和 Serverless 拓展,从而匹配业务增长?
-
计算和存储成本高昂
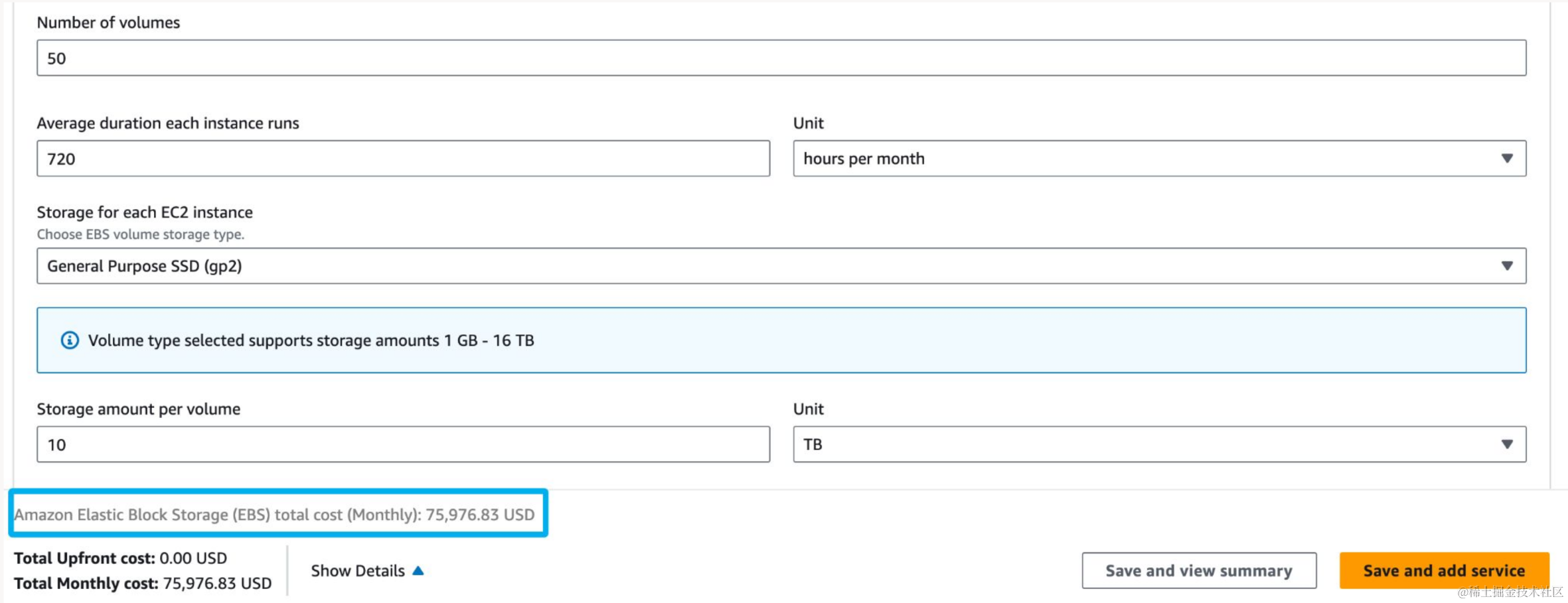
- 在企业的 IT 基础设施中,云厂商提供的计算和存储服务导致了高昂的成本。经测算,如果为 EC2 实例创建总容量为 500TB 的 SSD(GP2)存储,每个月在 EBS 服务上将会花费超过 7 万 5 千美元。如何才能在保证低廉成本的同时满足业务性能需求,提供经济、高效能的大数据架构?
-
大数据平台越来越复杂

- 上图是知名投资机构 a16z 绘制的统一数据基础设施架构全景图,不难看出,庞大的数据量和复杂的数据需求,导致大数据平台也变得日益复杂,需要数十种工具紧密协作,对于产品生态愈发严苛的要求。如何无缝与其他工具进行集成,并且复用现有基础设施?
大数据架构,能否完美实现
上述这些问题,为大数据架构提出了新的要求,特别是在以下几个维度上,能否做到“完美”实现 :
- 存储成本:极致低廉
- 计算控制:极致精细,支持算子在 Lambda 函数中运行
- 集群控制:极致弹性,按需伸缩、启停
- 架构特点:all-in-one platform,完全 Serverless 化
- 未来规划:为未来的云端大数据做好准备
传统数仓架构 vs. 弹性数仓架构
在进入到架构对比之前,我们先来看一个成本估测公式:Cost = Resource * Time ,也就是成本大致可以用资源与时间的乘积进行测算。
传统数仓架构
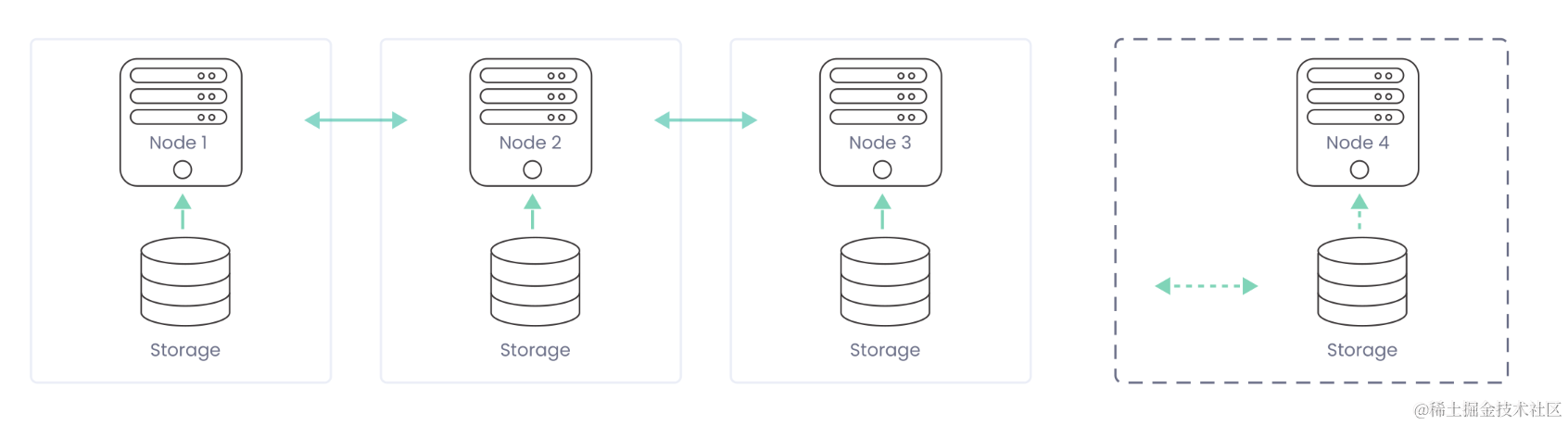
传统数仓往往采用 Shared-Nothing 架构,存储、计算一体化设计,弹性相对较弱。而且由于调度上采用资源固定(Fixed-Set)式调度策略,资源控制粒度粗,也会带来更多的成本。
对应到成本估测公式上,在时间一定的情况下,由于耗费资源数量较大,成本将会居高不下。
弹性数仓架构
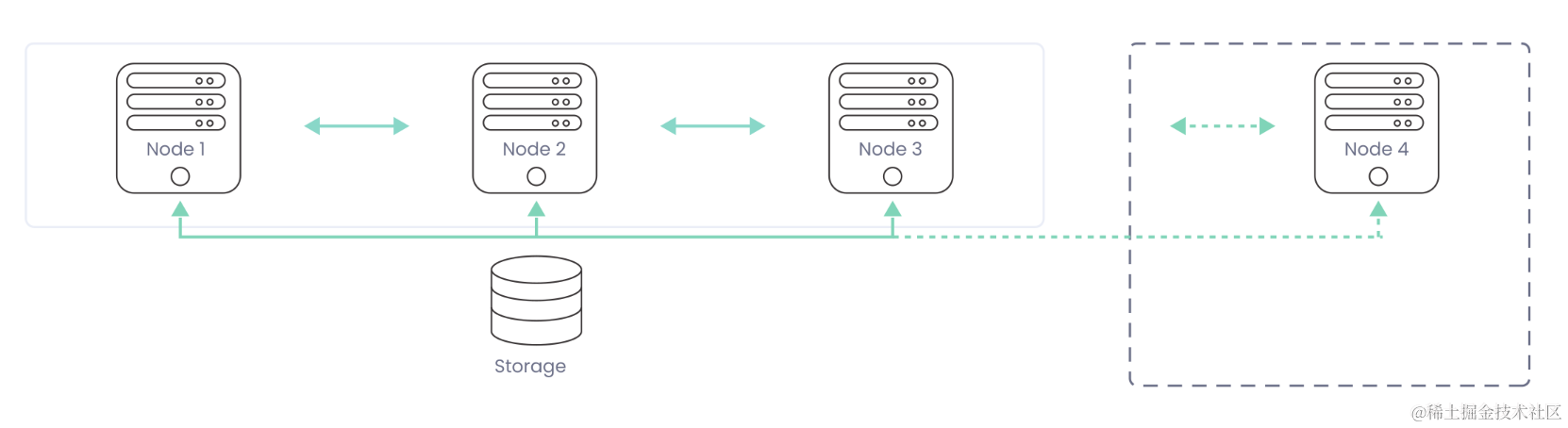
弹性数仓则采用 Shared-Storage 架构,底层可以使用对象存储,真正做到存储、计算分离,从而支持实时弹性扩容和缩容以及资源按需(Workload-Based)式调度,资源控制粒度更细。
对应到成本估测公式上,相较于传统数仓,弹性数仓的成本将会显著降低:存储成本可以按实际使用量折算,不需要为冗余的存储进行服务;而计算成本则根据业务需要实时调度,按需启停,按量计费,无需保有大量空闲计算资源。
Databend: 新一代云数仓架构设计
新一代云数仓的架构新在哪里?影响现代云数仓架构设计的因素和挑战都有哪些?这一部分将会给你答案。
新一代云数仓
现有数仓的局限
ClickHouse 是一款流行的开源数仓,以性能卓越著称。采用向量化计算技术,细节优化非常到位。具有 Pipeline 处理器和调度器以及 MergeTree + Wide-Column 存储引擎,单机性能非常强悍。
缺点: 分布式能力弱,无法应对复杂分析,运维复杂度高,不是为云设计。
Snowflake 则是一款云数仓,支持多租户,存储、计算分离。基于对象存储,存储介质便宜。弹性能力非常强悍,面向云架构设计。
缺点: 单机性能一般,比较依赖分布式集群能力。
Databend = ClickHouse + Snowflake + Rust
前面列出的是目前在开源和商业化领域领先的两款数仓产品,看上去性能和弹性无法兼得,想要低成本和弹性计算是不是就必须放弃单节点的极致优化呢?我们来看一下 Databend 交出的答卷。
- 借鉴 ClickHouse 向量化计算,提升单机计算性能。
- 借鉴 Snowflake 存储、计算分离思想,提升分布式计算能力。
- 借鉴 Git,MVCC 列式存储引擎,支持 Insert / Read / Delete / Update / Merge 等操作,以及 Time Travel 等高级特性。
- 全面支持 HDFS、基于云的对象存储、IPFS 等 20 多种存储协议。
- 基于便宜的对象存储也能方便的做实时性分析。
- 完全使用 Rust 研发(超过 33 万行代码),研发第一天就在 Github 开源。
- 高弹性 + 强分布式,致力于解决大数据分析成本和复杂度问题。
云数仓架构设计
Databend Cloud 架构全景图
Databend Cloud 是基于开源云原生数仓项目 Databend 打造的一款易用、低成本、高性能的新一代大数据分析平台,提供一站式 SaaS 服务,免运维、开箱即用。下面是 Databend Cloud 的架构全景图,也是 Databend Labs 团队对新一代云数仓的架构的设计与实现。
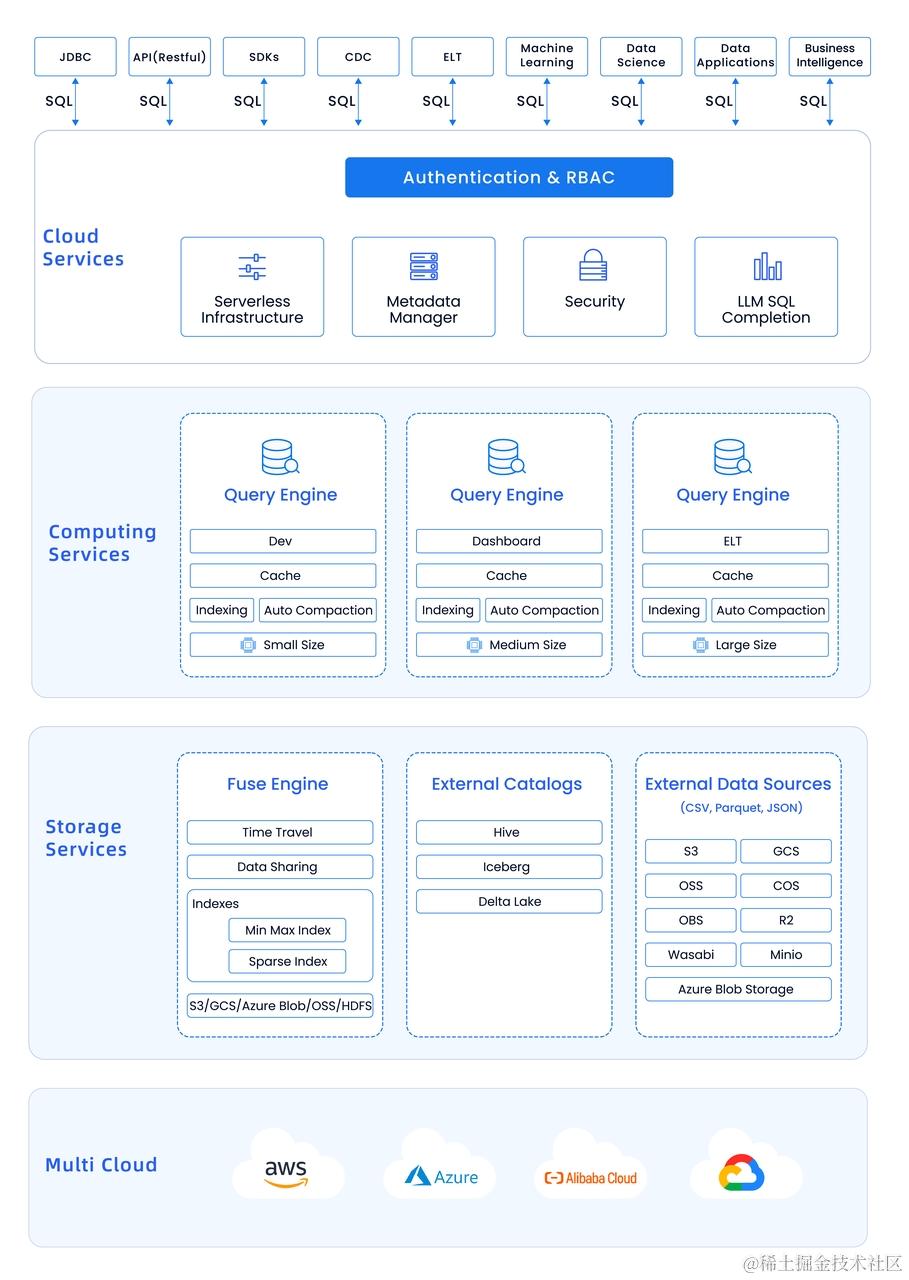
影响云数仓架构设计的因素与挑战
Databend / Databend Cloud 之所以演化出现在的架构,是因为新一代云数仓除了要在性能上比肩传统数仓、弹性上对标弹性数仓之外,还必须解决下面几个重要的问题:
- Ingest 海量数据网络费用问题:传统 INSERT 模式费用昂贵,需要一套基于 S3 的免费方案。
- 对象存储不是为数仓而设计,延迟和性能如何平衡:Network-Bound -> IO-Bound -> CPU-Bound。
- 如何让系统更加智能,根据查询模式自动创建索引:如何让某些场景的 Query 越跑越快...
- 如何面向 Warehouse + Datalake 双重需求设计?
前两个问题是云带来的挑战,而后两个问题将直面用户需求,一旦考虑清楚这些问题,云数仓的架构也就呼之欲出了。
Databend 生态全景图
数仓的产品的成败,除了本身的设计和实现之外,也非常依赖数据生态,其关键在于解决数据的输入与输出问题。
Databend 自身支持一定 ETL 能力,能够使用 Stage 和 Multiple Catalog 挂载外部数据源,提供全量、增量、条件等多种导入方式,支持使用 PRESIGN 上传和下载数据。
Databend 积极融入大数据生态,拓展「Databend 朋友圈」,提供全链路解决方案,帮助用户将数据转化为商业洞见。
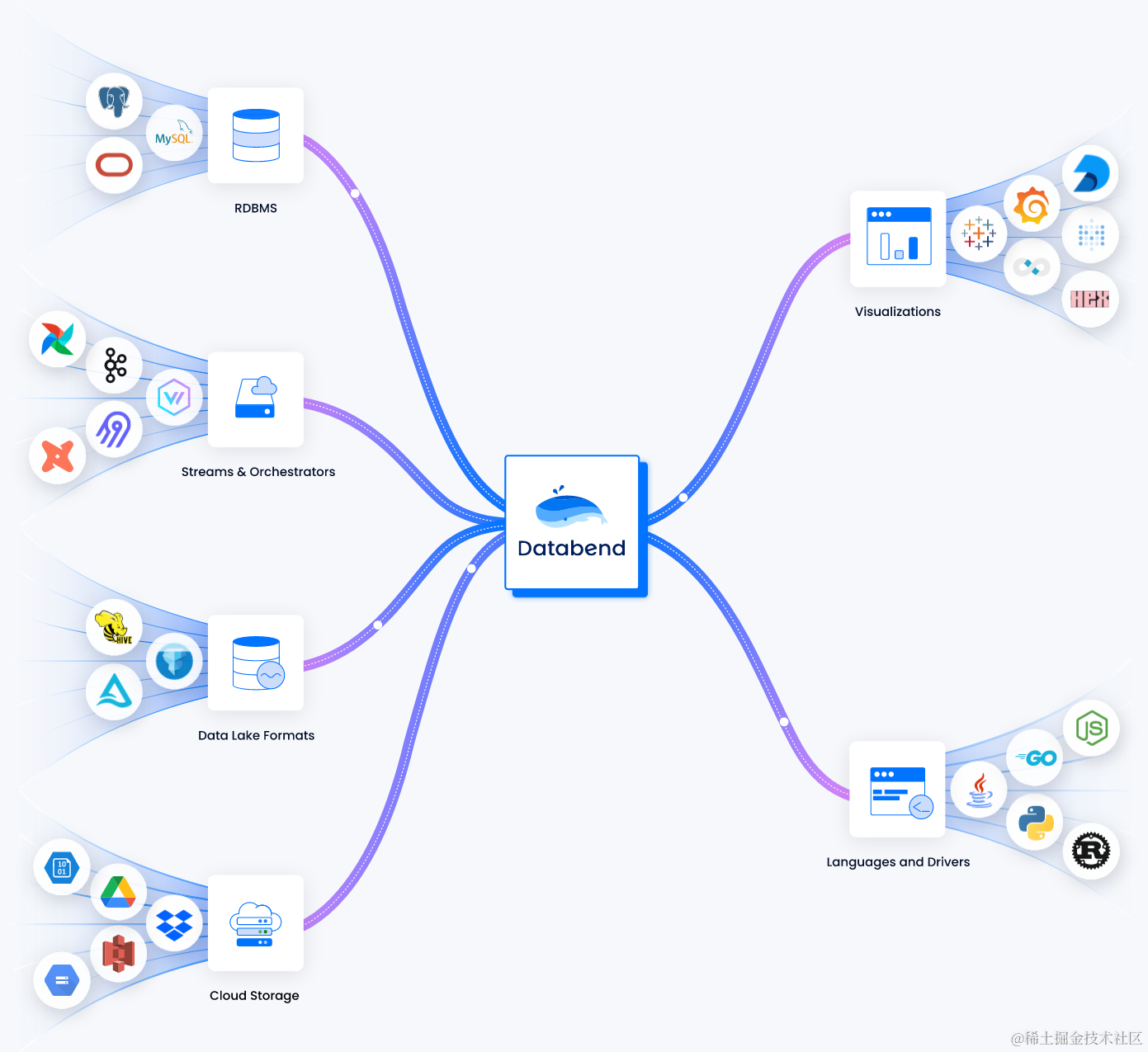
Databend 为用户提供价值
Databend 是一款开源、开放,运维简单、分钟级部署,为云端海量数据分析而设计的新一代云数仓。
我们在前面介绍了 Databend 的设计与实现,以及在生态方面做的一些努力,但产品是否能够占据市场、满足用户需求,还需要靠数据说话。
Databend v1.0 于 2023 年 3 月 5 日正式发布,目前处于 v1.2 版本,我们统计了以下几条关键数据:
- 替换 Trino/Presto 场景成本降低了 75%
- 替换 Elasticsearch 场景成本降低了 90%
- 归档场景成本降低了 95%
- 日志和历史订单分析场景成本降低了 75%
- ~1PB+/天(2023.9 统计)在使用 Databend 写入公有云对象存储
- 用户来自欧洲、北美、东南亚、印度、非洲、中国等地,每月节省数百万美元
以下是一些在生产环境中使用 Databend 的用户,感谢他们一直以来的支持与陪伴。我们将继续提供更有价值的服务。

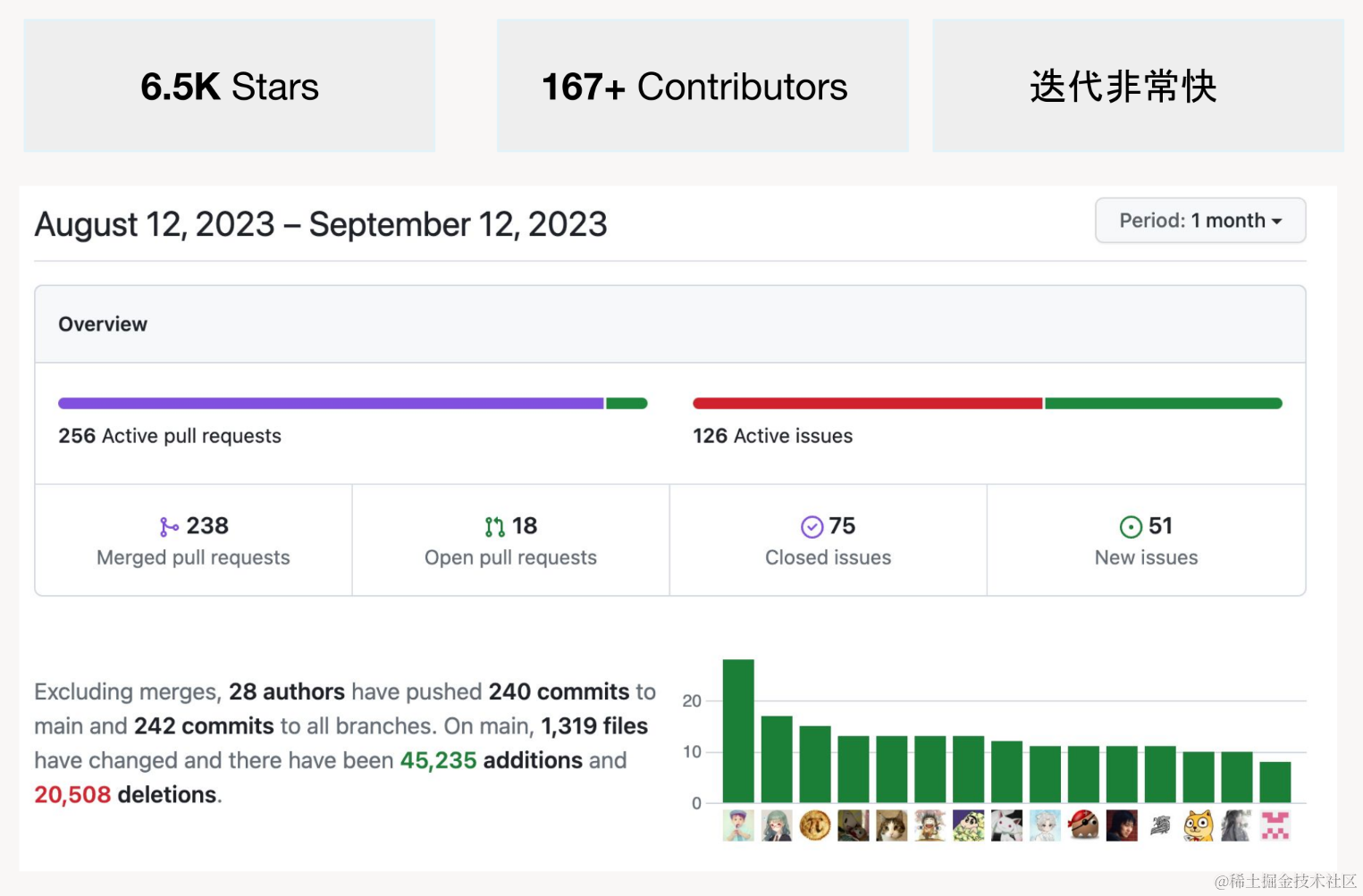
Databend 在开源社区
Databend 从第一天起就在 GitHub 上开源,目前已经成为 Rust 社区中的明星数据库项目。我们与上下游社区紧密协作,共同建设 Rust 大数据生态。Databend 目前的贡献者中不乏大公司背景,比如 SAP、Yahoo、Fortinet、Shopee、Alibaba、Tencent、ByteDance、EMQ、快手,Databend 社区正在被顶级需求、顶级场景驱动。
体验 Databend
最后,欢迎大家体验 Databend 产品与生态,与我们共同建设坚实可靠的大数据基础设施。
-
本地部署可以尝试我们的社区版本,官网地址是:https://docs.databend.cn。
-
同时,也欢迎访问 Serverless Cloud 体验 Databend 在云上的澎湃动力:
- 海外(AWS / GCP):https://app.databend.com
- 国内(阿里云 / 腾讯云 / 华为云):https://app.databend.cn
订阅我们的新闻简报
及时了解功能发布、产品规划、支持服务和云服务的最新信息!


